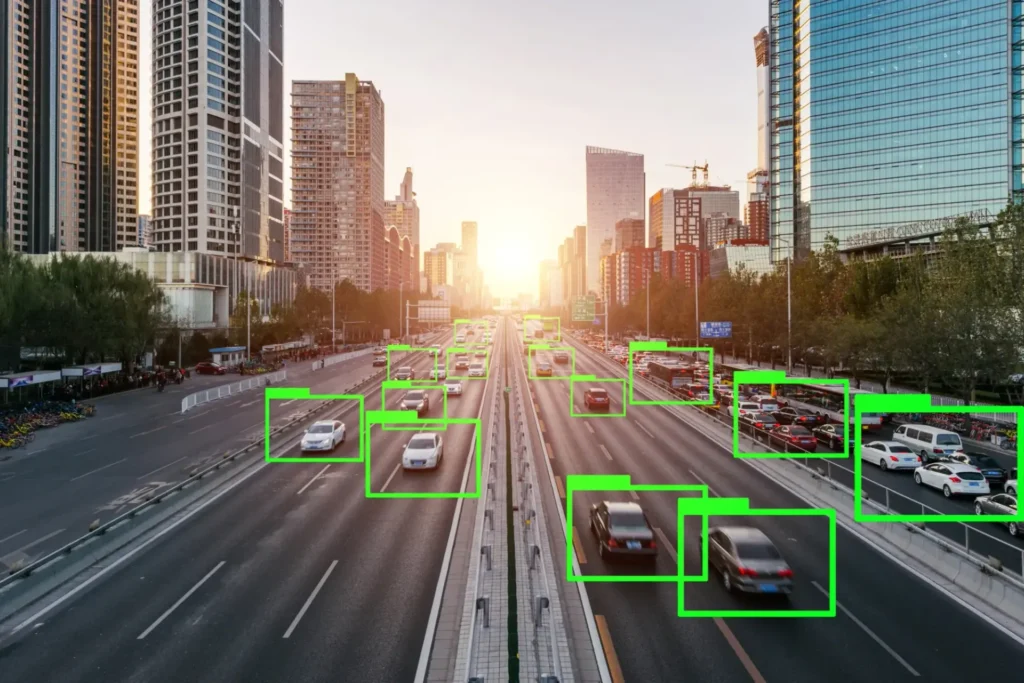
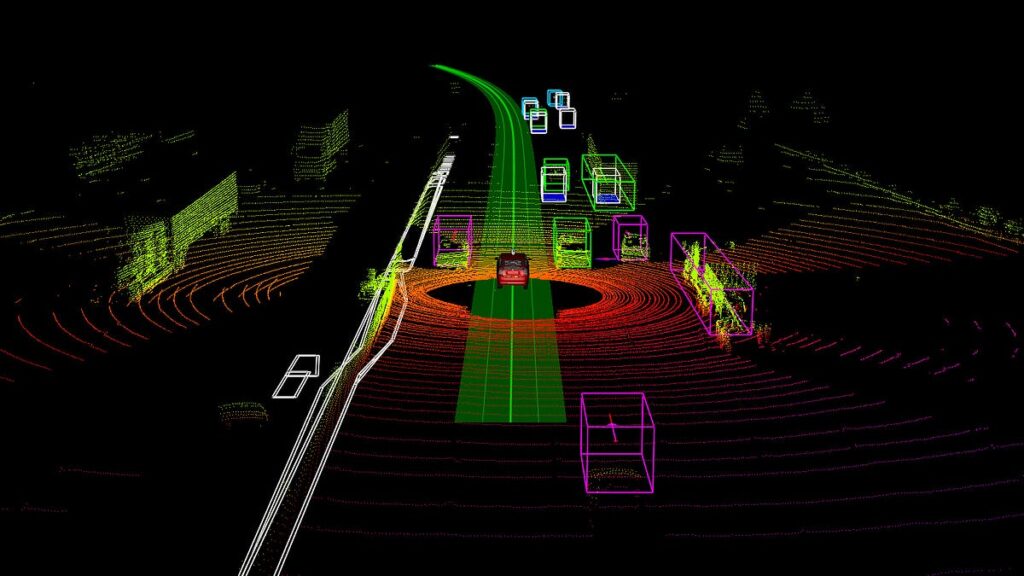
Hãy tưởng tượng bạn có thể ghi lại thế giới thực — từng khúc quanh của con đường núi, từng viên gạch của tòa nhà hàng trăm năm tuổi, hay từng góc phố nhộn nhịp — không phải dưới dạng hình ảnh, mà là hàng triệu điểm 3D nhỏ bé, chính xác đến từng chi tiết. Đó chính là điều kỳ diệu của dữ liệu đám mây điểm (point cloud).
Các đám mây điểm 3D này, thường được thu thập bằng cảm biến LiDAR, máy bay không người lái (drone), xe tự hành, hoặc máy quét mặt đất, cho phép chúng ta tái tạo kỹ thuật số các môi trường vật lý với độ chi tiết ấn tượng.
Tuy nhiên, dù dữ liệu đám mây điểm mở ra cánh cửa cho đổi mới, việc khai thác nó không hề đơn giản. Phân tích đám mây điểm tồn tại nhiều vấn đề phổ biến — những vấn đề có thể âm thầm phá hỏng toàn bộ quy trình làm việc nếu không được xử lý đúng cách: như sai số trong đo đạc, phân đoạn kém, nhận diện sai đặc trưng, và còn nhiều nữa.
Trong bài viết này, chúng ta sẽ cùng tìm hiểu những khó khăn thực sự khi làm việc với đám mây điểm, giải mã nguyên nhân của các thách thức đó, và đưa ra những phương pháp thực tiễn để khắc phục hiệu quả. Bài viết hướng đến cả người mới bắt đầu lẫn người dùng nâng cao, nhằm củng cố kiến thức về tác động và cách giảm thiểu rủi ro trong quy trình xử lý dữ liệu đám mây điểm.
Hiểu về Dữ liệu Đám mây Điểm (Point Cloud)
Trước khi đi sâu vào những vấn đề có thể gặp phải, chúng ta cần xây dựng nền tảng cơ bản: Dữ liệu đám mây điểm là gì?
Một cách đơn giản, đám mây điểm là tập hợp các điểm dữ liệu trong không gian 3D. Mỗi điểm có một vị trí xác định (tọa độ X, Y, Z) và có thể mang thêm thông tin như màu sắc, cường độ, độ phản xạ hoặc dấu thời gian (timestamp). Tập hợp các điểm này đại diện cho bề mặt bên ngoài của một vật thể hoặc cảnh quan trong thế giới thực.
Các đám mây điểm thường được tạo ra bằng các phương pháp sau:
- LiDAR (Light Detection and Ranging): Kỹ thuật cảm biến từ xa sử dụng tia laser để đo khoảng cách.
- Máy quét laser mặt đất (Terrestrial laser scanners): Thiết bị đặt trên mặt đất, thường dùng trong khảo sát, xây dựng hoặc phục dựng di tích.
- Photogrammetry từ máy bay/UAVs/drone: Thu thập hình ảnh từ trên cao để dựng mô hình 3D.
Những bộ dữ liệu thô này rất phong phú và chi tiết, nhưng đồng thời cũng phức tạp, thiếu sót và khó xử lý nếu không có các bước tinh chỉnh bổ sung.
Mốc quét (Scan datum) và điểm kiểm soát (Control points)
Căn chỉnh (alignment) là một trong những bước khó khăn nhất trong quá trình xử lý đám mây điểm, đặc biệt khi cần kết hợp nhiều bản quét thành một tập dữ liệu thống nhất.
Mỗi bản quét đám mây điểm thường có các mốc (datum) và điểm gốc khác nhau, cùng với các điểm kiểm soát cố định giúp gắn kết dữ liệu với hệ tọa độ thực tế. Nếu quá trình căn chỉnh gặp lỗi — ví dụ như các mốc quét bị lệch hoặc điểm kiểm soát được chọn không chính xác — toàn bộ tập dữ liệu có thể bị lệch vị trí hoặc biến dạng.
Đây là một vấn đề nghiêm trọng, đặc biệt khi thực hiện các dự án tái tạo quy mô lớn như bản đồ hóa đô thị chính xác hay kiểm định kết cấu hạ tầng.

Các lỗi phổ biến trong phân tích đám mây điểm (Point Cloud Analysis)
Hãy cùng điểm qua một số vấn đề thường gặp mà hầu hết các dự án phân tích đám mây điểm (point cloud) phải đối mặt. Dưới đây là danh sách những lỗi phổ biến trong phân tích đám mây điểm mà chúng ta sẽ tập trung:
Mật độ điểm và chất lượng dữ liệu
Hãy xem mật độ đám mây điểm giống như độ phân giải pixel trong một bức ảnh; nếu quá thấp, bạn sẽ mất đi các chi tiết, nếu quá cao, tệp sẽ trở nên cồng kềnh và khó xử lý.
Các đặc điểm như cạnh sắc nét, vật thể nhỏ hoặc các khe hẹp có thể bị thiếu nghiêm trọng trong các đám mây điểm có mật độ quá thấp.
Ngược lại, đám mây quá dày đặc sẽ làm chậm quá trình phân tích, tiêu tốn nhiều bộ nhớ và làm giảm hiệu suất tổng thể.
Chất lượng của dữ liệu thô cũng quan trọng không kém. Dữ liệu nhiễu do mưa, vật thể di chuyển hoặc bề mặt phản xạ có thể tạo ra các điểm “ma” và làm mờ các hình dạng quan trọng.
Thực hành tốt nhất: Hướng tới mật độ cân bằng, được tối ưu hóa cho nhiệm vụ cụ thể. Làm sạch dữ liệu nhiễu và loại bỏ các điểm ngoại lai bằng các bộ lọc để cải thiện phân tích.
Phân đoạn kém
Phân đoạn (segmentation) là quá trình chia đám mây điểm thành các phần có ý nghĩa, chẳng hạn như tách biệt con đường khỏi tòa nhà, hoặc phân biệt giữa cây cối và đèn giao thông.
Tuy nhiên, các cảnh quan trong thế giới thực thường bị làm mờ bởi bóng đổ, các phần bị che khuất, lỗi quét và hình học phức tạp. Các thuật toán phân đoạn kém có thể xử lý sai đối tượng bằng cách gộp nhiều thứ lại với nhau hoặc chia chúng theo những cách bất thường, dẫn đến phân tích sai lệch hoặc lỗi trong các mô hình phía sau.
Ví dụ, nếu việc phân đoạn không chính xác, một chiếc xe tự lái có thể nhầm biển báo giao thông là một phần của cái cây gần đó.
Khuyến nghị: Sử dụng các mô hình phân đoạn dựa trên học sâu (deep learning) và kết hợp dữ liệu từ nhiều cảm biến khác nhau để đạt độ chính xác cao hơn.

Lựa chọn thuật toán phù hợp cho nhiệm vụ
Phân tích đám mây điểm không tuân theo một quy tắc chung nào cả. Thuật toán dùng để phát hiện tán cây trong một nghiên cứu môi trường sẽ không hiệu quả nếu áp dụng để phát hiện ổ gà trên đường cao tốc.
Tuy nhiên, một sai lầm phổ biến là nhiều người thường áp dụng các thuật toán có sẵn (off-the-shelf) cho những nhiệm vụ rất cụ thể.
Việc sử dụng sai thuật toán có thể dẫn đến hiệu suất phần mềm kém, hiểu sai các đặc điểm dữ liệu, và bỏ lỡ các cơ hội tối ưu hóa.
Hãy tự đặt ra câu hỏi:
- Ứng dụng của bạn có yêu cầu xử lý thời gian thực (ví dụ: xe tự lái) hay có thể xử lý ngoại tuyến?
- Bạn đang làm việc trong môi trường trong nhà hay các không gian ngoài trời rộng lớn?
- Trường hợp sử dụng của bạn có yêu cầu độ chính xác cao (ví dụ: khảo sát địa hình) hay mang tính chất diễn giải (ví dụ: trò chơi, thực tế ảo)?
Gợi ý: Luôn lựa chọn thuật toán phù hợp với nhiệm vụ cụ thể, và kiểm thử nó trên các tập dữ liệu đại diện trước khi mở rộng quy mô.
Phân đoạn ngữ nghĩa và phân loại sai
Phân đoạn ngữ nghĩa (semantic segmentation) là bước tiến xa hơn so với phân đoạn thông thường — nó gán nhãn cho từng điểm trong đám mây điểm với một danh mục cụ thể như: đường, người đi bộ, xe hơi, cột điện, cây cối, v.v.
Tuy nhiên, ngay cả các mô hình AI mạnh mẽ cũng có thể bị nhầm lẫn. Những điểm nằm gần nhau về mặt không gian nhưng khác nhau về mặt ngữ nghĩa (ví dụ: một người đứng cạnh bức tường) có thể bị phân loại sai do nhiễu, dữ liệu không đầy đủ, hoặc thiếu hiểu biết theo ngữ cảnh.
Việc phân loại sai không chỉ gây phiền toái — nó có thể dẫn đến hậu quả nghiêm trọng. Ví dụ, nếu một chiếc xe tự hành nhầm lẫn một đứa trẻ với biển báo giao thông, hậu quả có thể rất thảm khốc.
Cách khắc phục: Huấn luyện mô hình trên các bộ dữ liệu phong phú, được gán nhãn chất lượng cao. Kết hợp dữ liệu từ cảm biến LiDAR với hình ảnh từ camera (sensor fusion) để tăng độ chính xác ngữ nghĩa.
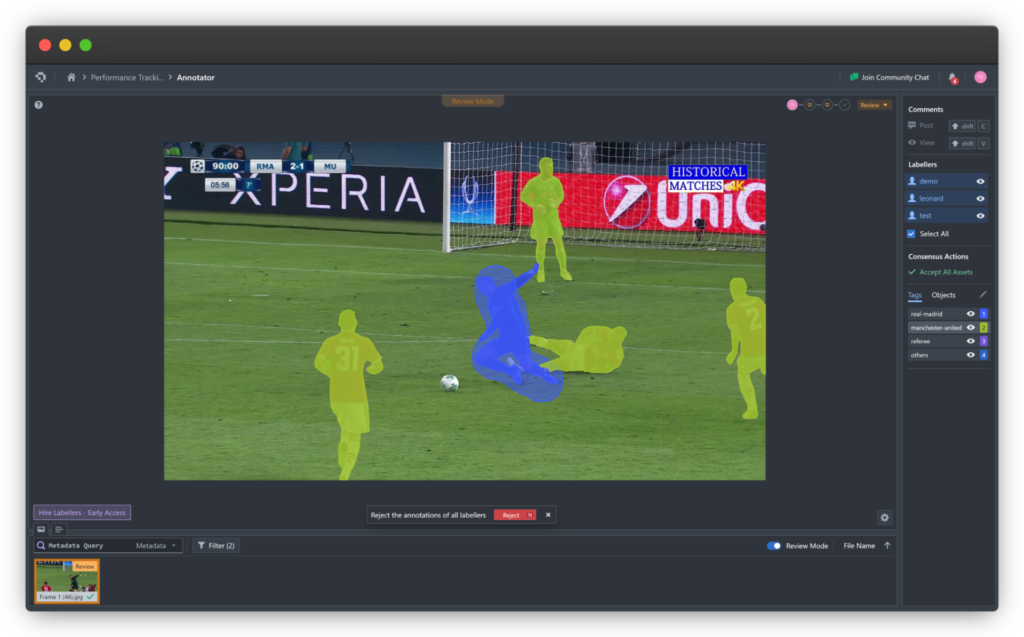
Những rủi ro trong việc gán nhãn đám mây điểm (Point Cloud Annotation)
Mọi mô hình AI chỉ hiệu quả nếu được huấn luyện trên dữ liệu chất lượng — và điều đó bắt đầu từ việc gán nhãn chính xác. Dưới đây là ba thách thức quan trọng trong quá trình gán nhãn:
- Độ chính xác của nhãn (Labeling Accuracy): Gán nhãn không nhất quán hoặc cẩu thả có thể gây nhầm lẫn cho mô hình, làm giảm hiệu suất.
- Dữ liệu thưa thớt hoặc nhiễu (Sparse or Noisy Data): Việc gán nhãn cho các đối tượng thưa, trùng lặp hoặc nhiễu là một công việc phức tạp và dễ sai sót.
- Tính nhất quán của bộ dữ liệu (Dataset Consistency): Khi nhiều người gán nhãn cùng một dữ liệu mà không có hướng dẫn tiêu chuẩn, kết quả sẽ là một tập dữ liệu huấn luyện rời rạc, thiếu đồng bộ.
Mẹo chuyên nghiệp: Hãy xây dựng một quy trình gán nhãn chặt chẽ với các bước kiểm tra chất lượng (QA), đào tạo người gán nhãn, và sử dụng công cụ tự động để đảm bảo tính nhất quán.
Bạn có thể thử Coral Mountain Data cung cấp giải pháp gán nhãn dữ liệu LiDAR và 3D giúp tự động hóa, rà soát và xác thực dữ liệu nhanh chóng, hiệu quả hơn.
Các phương pháp và kỹ thuật để vượt qua những cạm bẫy
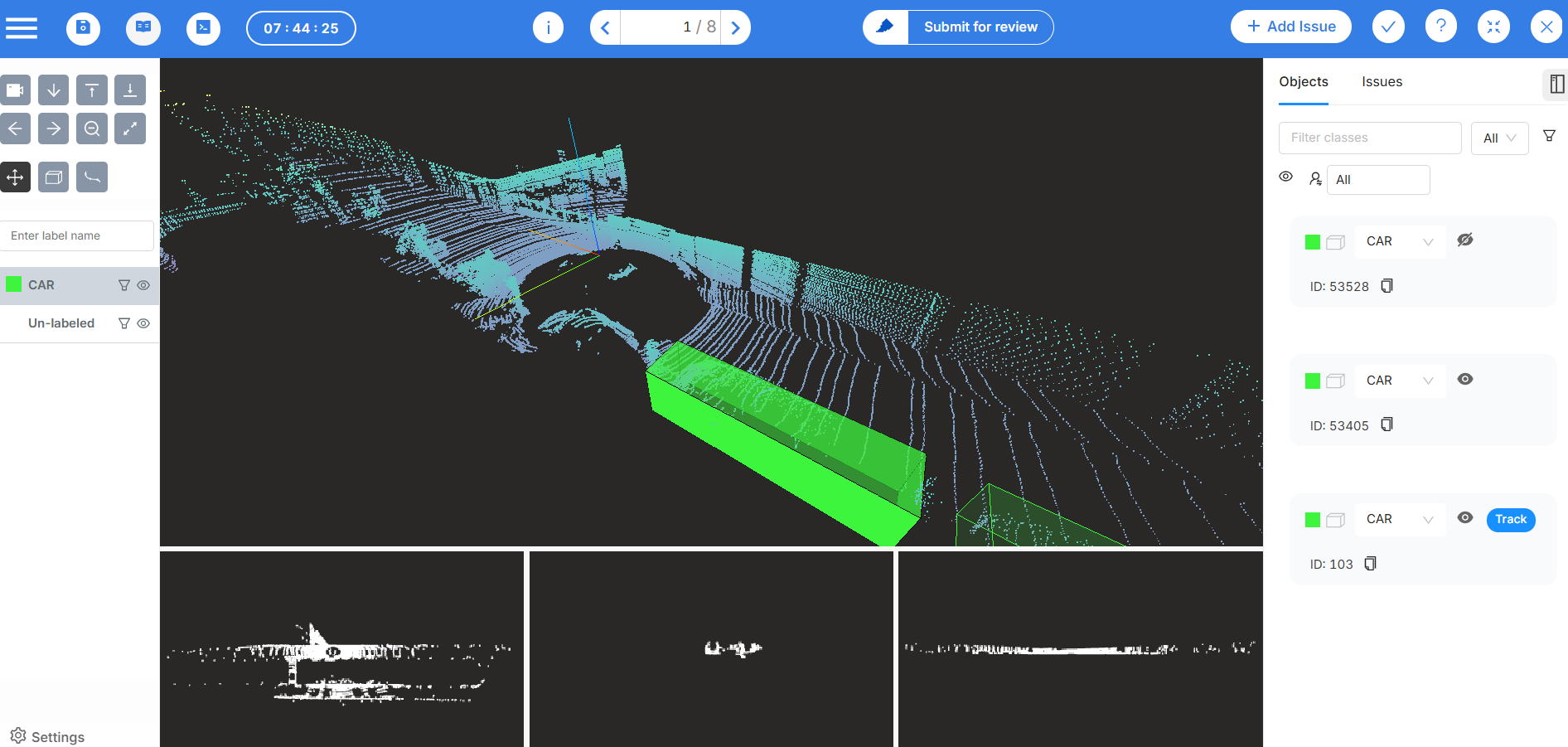
Giờ đến tin tốt — mọi rủi ro mà chúng ta đã đề cập đều có giải pháp. Hãy cùng khám phá cách để tránh các vấn đề đó và nâng cao giá trị dữ liệu đám mây điểm (point cloud) của bạn.
Lọc nâng cao & lựa chọn thuật toán
Bắt đầu bằng việc đầu tư vào các bộ lọc tiền xử lý để làm sạch dữ liệu đám mây điểm thô. Những bộ lọc này có thể bao gồm:
- Loại bỏ điểm ngoại lệ (Outlier removal)
- Lọc nhiễu thống kê (Statistical noise filtering)
- Làm mượt dữ liệu (Smoothing)
- Giảm mật độ dữ liệu (Downsampling)
Sau bước này, hãy sử dụng các thuật toán phù hợp với từng nhiệm vụ cụ thể như phân đoạn (segmentation), trích xuất đặc trưng (feature extraction) hoặc mô hình hóa (modeling). Kết hợp giữa phương pháp theo kinh nghiệm (heuristic) và phương pháp học máy (learning-based) sẽ mang lại kết quả tối ưu.
Cách tiếp cận kết hợp (hybrid approach) thường đem lại hiệu quả cao nhất.
Ví dụ:
- Dùng phương pháp dựa trên quy tắc để xác định các điểm thuộc mặt đất
- Sau đó, sử dụng mạng nơ-ron để phân loại các cấu trúc phức tạp nằm phía trên mặt đất
Tận dụng LiDAR và các cảm biến thông minh
Không phải cảm biến nào cũng giống nhau. Các cảm biến LiDAR hiện đại cung cấp độ chính xác ở mức milimét, khả năng thu hồi nhiều tín hiệu (multiple returns) và nhận thức độ sâu có màu sắc (colorized depth perception).
Hãy lựa chọn cảm biến dựa trên các yếu tố sau:
- Tầm quét và độ phân giải yêu cầu
- Điều kiện môi trường (ví dụ: mưa, sương mù)
- Tốc độ khung hình và chu kỳ làm mới
Và đừng quên hiệu chuẩn (calibration)! Cảm biến bị lệch có thể khiến toàn bộ dữ liệu bị sai lệch nghiêm trọng.
Việc kết hợp LiDAR với camera RGB, IMU (đơn vị đo quán tính), hoặc GNSS (hệ thống định vị toàn cầu) có thể tạo ra các đám mây điểm phong phú và có ngữ cảnh, giúp nâng cao cả độ chính xác và khả năng diễn giải dữ liệu.
Công cụ gán nhãn thông minh
Để vượt qua sự mệt mỏi và thiếu nhất quán trong quá trình gán nhãn, hãy sử dụng các công cụ sau:
- Gán nhãn bán tự động được hỗ trợ bởi AI
- Nội suy (interpolation) giữa các khung hình trong các cảnh động
- Gán nhãn theo mẫu cho các hình mẫu lặp lại
- Bảng điều khiển kiểm soát chất lượng (QA dashboards) để đảm bảo tính nhất quán giữa các người gán nhãn
Mục tiêu là giúp quá trình gán nhãn trở nên nhanh hơn, thông minh hơn và chính xác hơn — thay vì trở thành điểm nghẽn trong quy trình của bạn.
Bạn có thể thử Coral Mountain Data cung cấp giải pháp gán nhãn Lidar hiệu quả cho khách hàng để cải thiện hiệu suất.
Kết luận
Phân tích đám mây điểm (point cloud) là một trong những công cụ mạnh mẽ nhất hiện nay để hiểu và tương tác với thế giới 3D. Từ dẫn đường tự động đến mô hình song sinh kỹ thuật số (digital twins), tiềm năng là vô hạn — nhưng chỉ khi bạn xử lý các thách thức một cách cẩn trọng.
Khi công nghệ ngày càng phát triển và các trường hợp ứng dụng trở nên phức tạp hơn, cách tiếp cận phân tích đám mây điểm của chúng ta cũng cần được nâng cao. Độ chính xác, khả năng thích ứng và nhận thức theo ngữ cảnh là chìa khóa.
Nếu bạn đang làm việc với dữ liệu 3D — dù trong lĩnh vực di chuyển, xây dựng, giám sát hay thực tế ảo — hãy đối xử với đám mây điểm bằng sự kỹ lưỡng mà nó xứng đáng nhận được. Nhận diện các sai sót thường gặp, áp dụng các phương pháp tốt nhất và tiếp tục tiến về phía trước.
Bởi lẽ, trong một thế giới ngày càng được định hình bởi các môi trường số, mọi điểm đều có giá trị.