With data security becoming one of the biggest concerns in AI projects today, a new decentralized way of training ML models is emerging as a promising solution: Federated Learning (FL).

Federated Learning
Federated Learning was first introduced by Google in 2016 through a blog post and later in a landmark research paper. Since then, the concept has grown rapidly and is now seen as one of the most privacy-friendly ways of training AI systems.
In essence, Federated Learning allows machine learning models to be trained collaboratively without transferring the underlying data. Instead of pooling raw data into one central place, FL enables algorithms to learn from data spread across different locations. This makes it possible for multiple organizations to train shared models without exposing sensitive data, which is especially valuable in industries such as healthcare and finance.
Some key situations where FL shines include:
- Privacy-sensitive environments: Data never leaves the device or server where it originates.
- Geographically distributed data: Models can learn from global datasets while respecting local storage.
How does Federated Learning work?
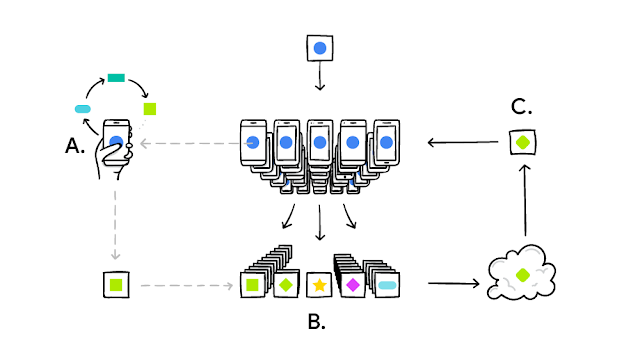
Here’s a simplified breakdown of the process:
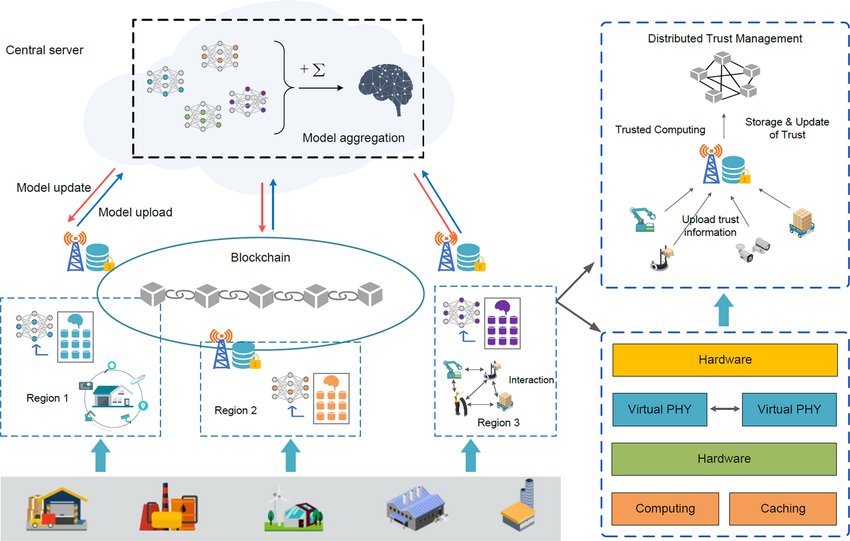
- A central server distributes a base ML model to participating devices (phones, laptops, IoT systems, etc.).
- Each device trains this model locally using its private data. Only the updated parameters are changed—not the raw data.
- Devices send their updated model parameters back to the central server.
- The central server aggregates all updates, combining knowledge from each device.
- A new global model is produced and redistributed back to devices for the next training cycle.
This loop repeats until the global model reaches the desired performance.
Difference between Federated Learning and Traditional ML Training
Traditional machine learning usually depends on a centralized pipeline: raw data is collected from multiple devices and sent to a central server where the model is trained. The trained model then returns to the devices. This architecture has two drawbacks:
- It requires sending sensitive data to a central location, raising privacy concerns.
- It slows down real-time learning due to constant data transfer.
Federated Learning, in contrast, allows the training to happen on-device. Updates are shared instead of raw data. These updates are averaged by the central server to build a stronger global model. This not only strengthens collaboration but also ensures that sensitive information never leaves its original source.
Why is this important?
Federated Learning matters for several reasons:
- Collaborative learning: Multiple organizations and devices can contribute to model training without data exposure.
- Edge-based training: Models run directly on devices like smartphones, medical equipment, or IoT systems.
- Real-time prediction: Since models live on the device, predictions can be made instantly—even offline.
- Lightweight infrastructure: Training doesn’t require heavy centralized servers; mobile-grade hardware often suffices.
Challenges in Federated Learning
Despite its promise, FL faces real hurdles:
- Device variability: Different devices have different storage, compute power, and network capabilities.
- Update security: Even sharing model updates can leak sensitive information if not handled properly.
- Non-uniform data: Data stored across devices can vary widely in format and quality, which can impact accuracy.
The FL research community is actively tackling these issues, and progress is being made rapidly. If you want a lighter take, Google even published a manga-style explanation of the concept—worth checking out!
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….