Let’s take a closer look at the fundamentals of data labeling: what it means, the different categories it falls into, and how it is used in real-world AI applications.
Data labeling: A quick overview
Data labeling is the process of tagging raw data—whether text, audio, images, or video—so that machine learning (ML) models can learn to interpret and understand it. Without labeled examples, most algorithms would have no frame of reference to distinguish one input from another.
This process is a cornerstone of Supervised Learning, where models rely on labeled datasets to make predictions or classifications.
For instance, to develop an AI that can detect cats in photos, you need to provide thousands of labeled images—some containing cats, others without. Over time, the system learns the unique features of cats, such as shape, color, and posture. Once trained, the model can generalize this knowledge and recognize cats in new, unseen images.

Data labeling: Types and Use-cases
The type of labeling depends largely on the format of the data and the intended application. Below are the main categories, along with examples of how they are applied in practice.
Sequencing
This involves marking boundaries and labels within sequential data such as text, speech, or time-series signals. It defines where an entity starts, ends, and how it should be tagged.
Use-cases:
- Identify a person’s name, company, or location in text (Named Entity Recognition).
- Highlight important clauses in legal contracts.
- Detects events within medical sensor data, such as irregular heartbeats.

Categorization
Data samples are assigned to one or more predefined classes. The classification can be binary (yes/no) or multi-class, with or without hierarchical structure.
Use-cases:
- Classify emails into “spam” or “not spam.”
- Assign sentiment labels (positive, neutral, negative) to customer reviews.
- Categorize online products into structured taxonomies, such as electronics, clothing, or home goods.
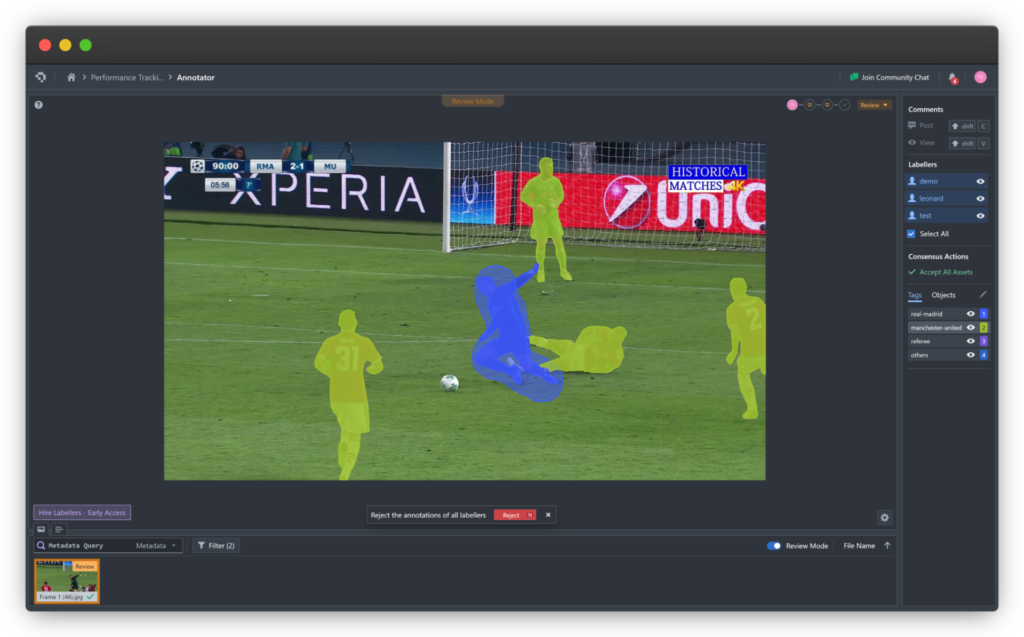
semantic-segmentation-oranges
Semantic segmentation helps AI models understand object boundaries and regions in an image
Segmentation
Segmentation involves dividing data into meaningful parts. In computer vision, it often means marking precise boundaries of objects within an image, while in speech processing it could mean separating voices or phrases.
Use-cases:
- Detect lane markings, pedestrians, and vehicles in traffic scenes.
- Separate speakers in a recorded meeting.
- Split documents into structured paragraphs for easier processing.
Mapping
This refers to transforming one type of data into another, often through translation or normalization. It helps standardize information or make it more usable for downstream systems.
Use-cases:
- Translate a French sentence into English.
- Summarize a lengthy article into a few sentences.
- Normalize addresses, phone numbers, or dates into a consistent format.
Intent extraction
Intent extraction focuses on identifying the underlying purpose behind a text or spoken command. This is especially common in natural language processing (NLP) applications.
Use-cases:
- In the sentence “Remind me to call the doctor tomorrow,” the intent is “set a reminder.”
- In “Order a large pizza,” the intent is “place an order.”
- Frequently applied in chatbots, digital assistants, and automated customer support.
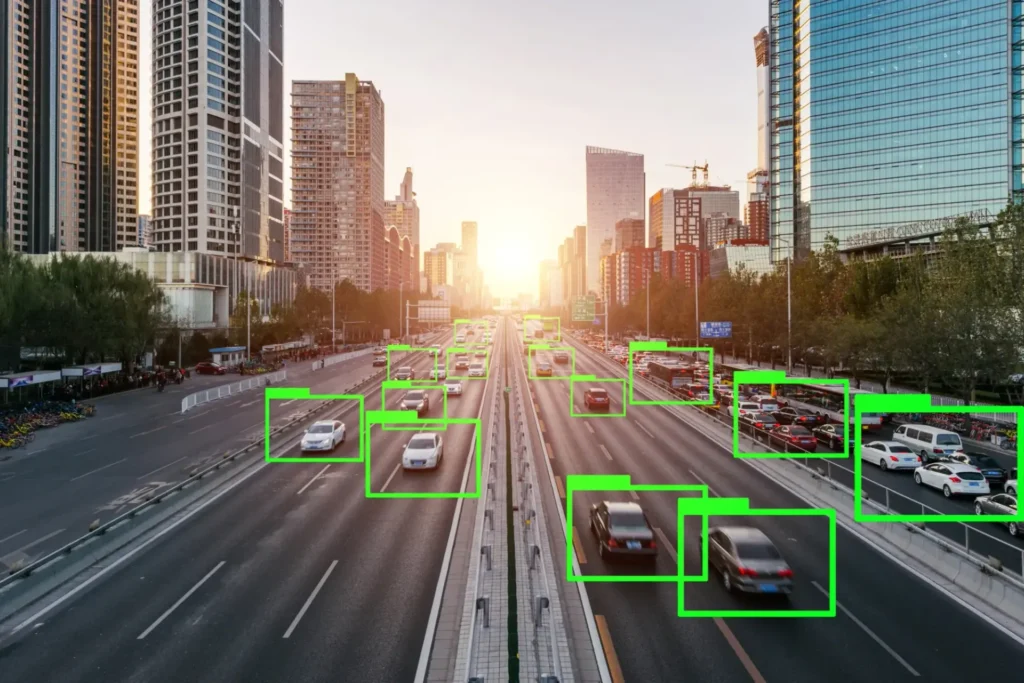
Object Detection
Object detection combines localization and classification—it identifies what objects are present and where they are within an image or video frame.
- Images: Models can detect pedestrians, cars, traffic lights, or animals.
- Use-cases: Applied in smart surveillance, quality control in manufacturing, and retail shelf analysis to track product availability.
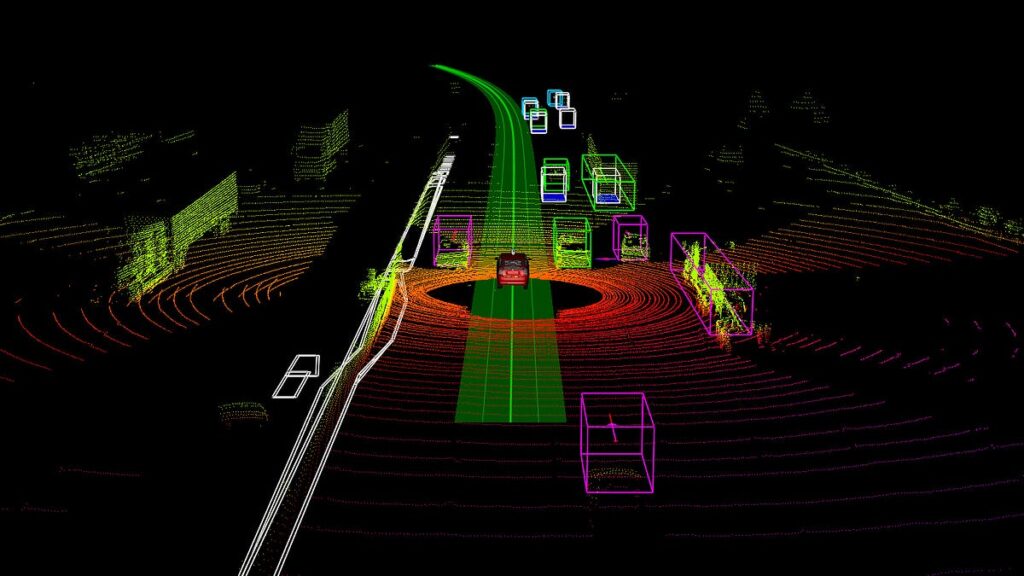
3d-pointcloud-annotation
3D point clouds enable machines to understand the physical environment in fine detail
- 3D point clouds: Generated by sensors such as LiDAR, which send laser pulses and measure the reflections to reconstruct the surrounding environment.
- Use-cases: Widely used in autonomous driving to detect obstacles and road boundaries, in drones for terrain mapping, and in robotics for navigation in complex spaces.

Coral Mountain Data is a company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models.