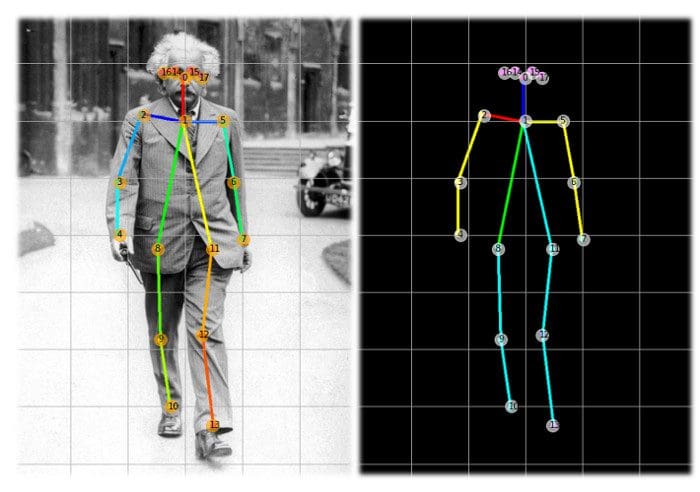
What is Data Centric Machine Learning? And how can it be utilised in practice?
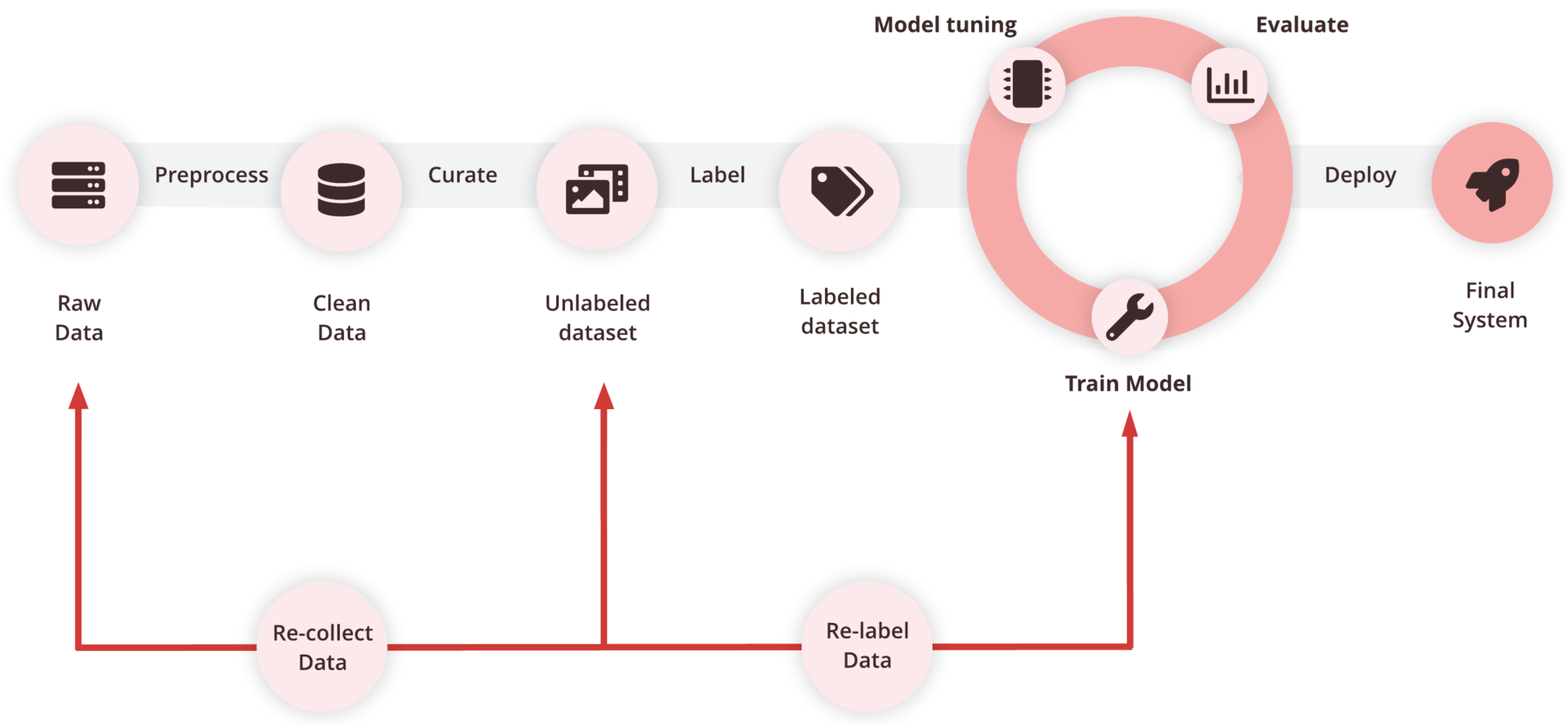
The Data Centric approach to ML introduces an additional data improvement loop into the standard model development lifecycle. Instead of treating data as a static resource and focusing all efforts on tweaking model architectures, this methodology shifts the attention towards actively refining data quality over time. In traditional ML workflows, teams repeatedly adjust models while relying on a fixed dataset. The Data Centric approach expands this cycle by continuously reviewing, cleaning, and upgrading data — ultimately allowing the model to learn from clearer, more representative inputs.
Why should I care about Data Centric Machine Learning?
The difference between building an AI system in a controlled environment and deploying one in the real world is enormous. Studies indicate that as many as 90% of AI initiatives never reach production, largely because the data used for training during development does not reflect real-world conditions. Models may perform impressively in testing but often fail once exposed to noisy, messy, and unpredictable data from real users.
Modern ML architectures are already highly capable at tasks like image recognition, speech processing, and text generation. At this stage, squeezing out gains by adjusting model parameters is far less impactful than improving what the model learns from. That’s why Data Centric ML is becoming the most practical path forward.
In practical terms, what does Data Centric ML entail?
(Advertisement placeholder removed for clarity — cost estimator CTA omitted.)
Data volume and curation
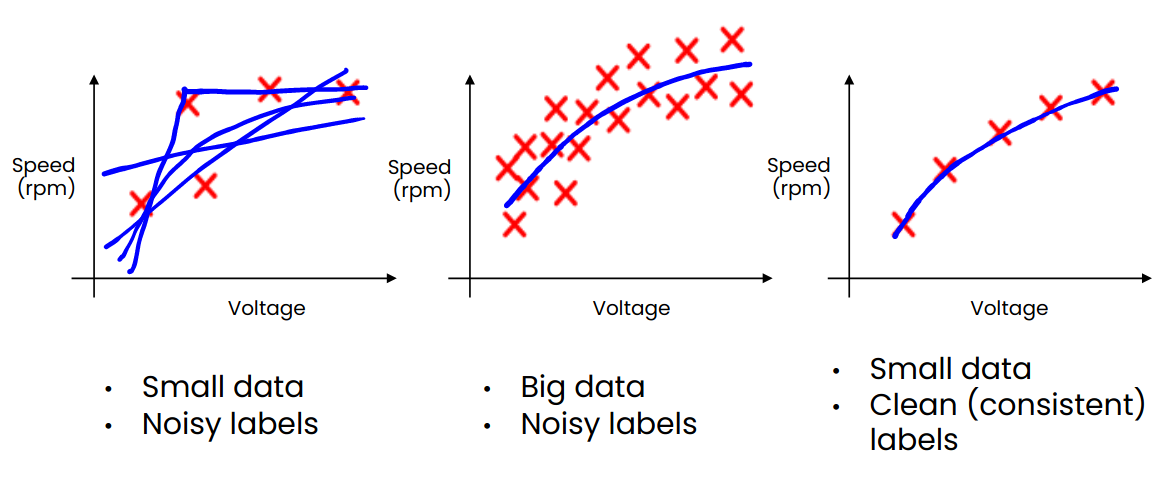
The amount of data used for training plays a crucial role in model performance — but quality becomes even more critical when datasets are small. Large datasets can sometimes hide inconsistencies or errors, while smaller datasets amplify them. Instead of collecting as much data as possible without direction, it is more effective to analyze where the model struggles and intentionally curate data to fill those gaps.
For example, if a model fails in low-light settings or snowy conditions, adding more examples from those environments can lead to significant improvements. Thoughtful data selection is far more efficient than blind data accumulation.
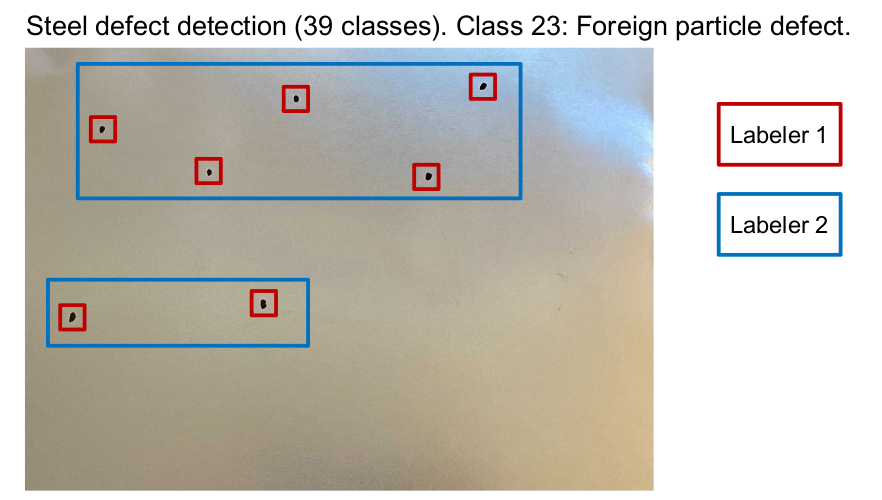
Label inconsistency
Data consistency — especially in labeling — is a deciding factor in model accuracy and reliability. Even subtle differences in how annotators interpret rules can derail training and produce misleading evaluation results.
At Coral Mountain, we recommend the following best practices to maintain label consistency:
- Label a small subset yourself before creating guidelines. This reveals ambiguous cases early.
- Measure label quality regularly through methods such as:
- Random reviews of completed annotations
- Honeypot testing: label a portion of the data internally, send it mixed with the dataset to annotators, and compare results afterward
- If inconsistencies persist, use multiple annotators per item and rely on majority voting for the final ground truth.
Data quality
As mentioned earlier, noisy labels have a much greater negative impact when the dataset is small. A few incorrect labels among 1,000 samples can outweigh dozens among 10,000. To ensure high-quality data:
- Definitions must be clear and unambiguous — annotators should interpret labels the same way.
- Coverage must be comprehensive — the data should reflect all key scenarios expected in deployment.
- Training data must stay updated — if real-world conditions evolve, so should the dataset.
Measuring data quality is a challenge when ground truth is unavailable, but both quantitative and qualitative methods — such as agreement rates, manual inspection, or confidence scoring — can help track improvement over time.
How can I get started with Data Centric ML?
The suggestions above are enough to begin applying the Data Centric mindset in your workflow, but they only scratch the surface. To dive deeper, you can explore curated research papers and recommended tools commonly used in data auditing, curation, and annotation workflows.
Coral Mountain also encourages joining the wider AI community — whether on Reddit or LinkedIn — to exchange learnings, troubleshoot challenges, and discover best practices shared by others on the same journey.
Happy building — and may your data be ever clean!
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….