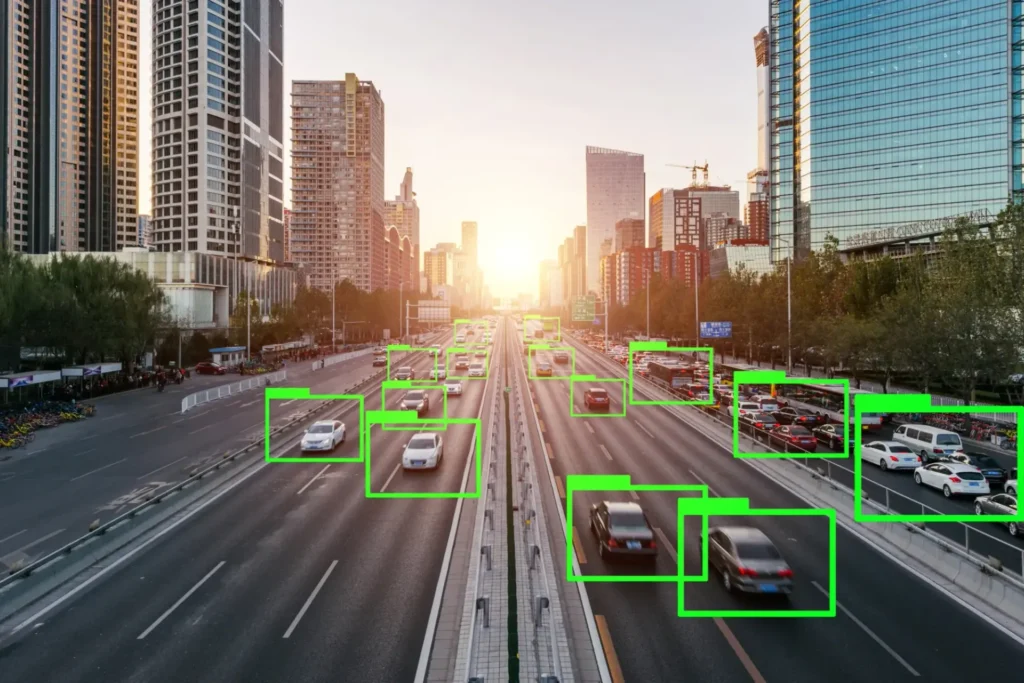
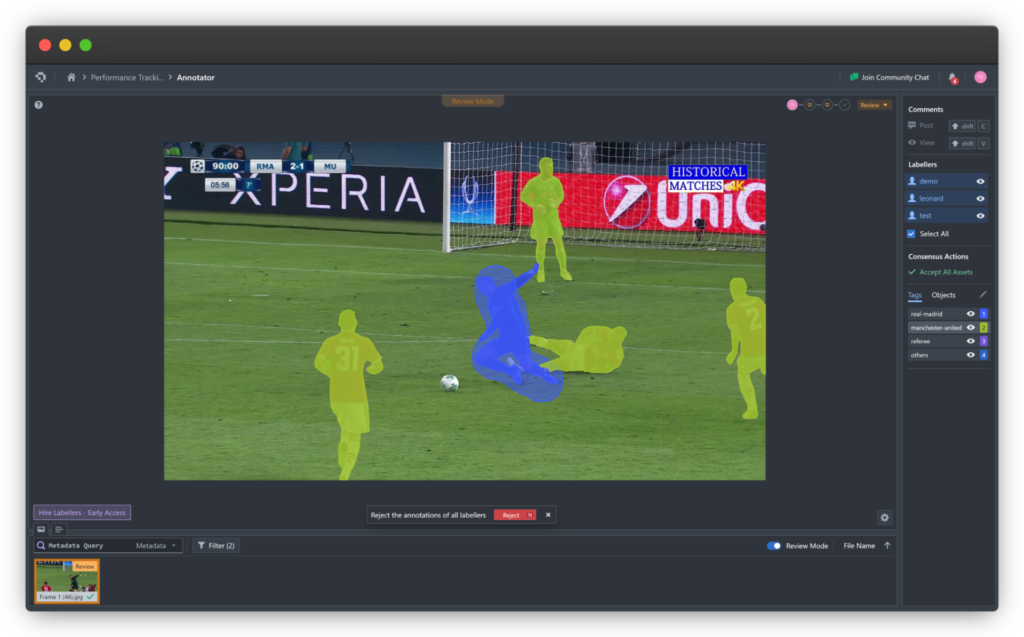
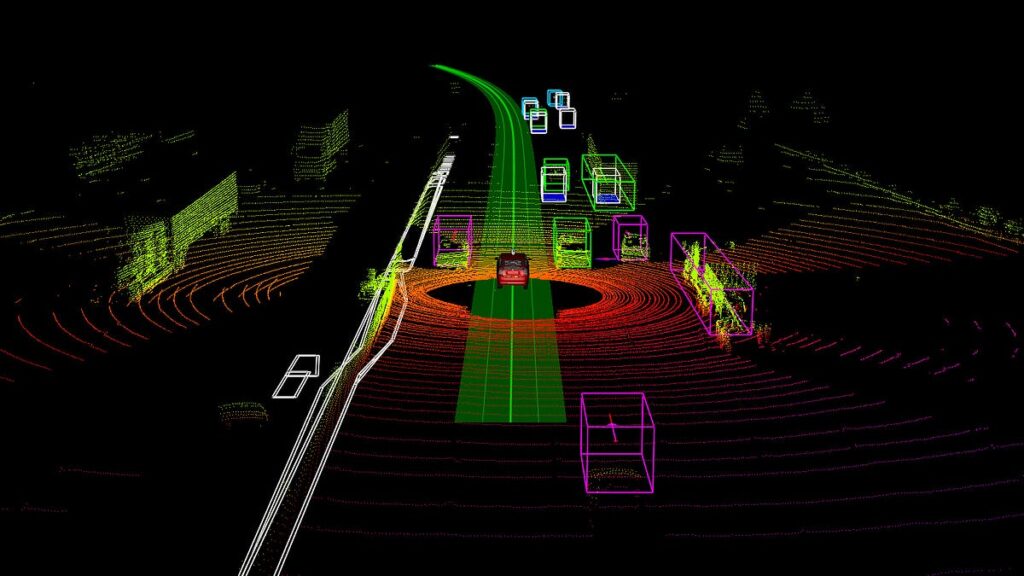
Before analyzing errors, it’s essential to understand the nature of the data. A point cloud is a set of vectors in three-dimensional space, with each point defined by (X, Y, Z) coordinates. Additional attributes may include color (RGB), laser reflectivity, or timestamps. Together, they represent the surface geometry of an object or environment.
Main data collection methods include:
- LiDAR (Light Detection and Ranging): Uses laser pulses to measure distances with high precision.
- Terrestrial Laser Scanning: Stationary ground-based systems used in topographic surveys, construction, and heritage conservation.
- Photogrammetry: Reconstructs 3D models from multiple 2D images captured from different angles, often by drones.
Although highly detailed, raw data from these sources often contains inconsistencies. One of the most fundamental challenges is ensuring spatial consistency when merging multiple scans. Each scan has its own coordinate system and origin. To form a unified model, precise alignment via control points is required. If misaligned or based on inaccurate control points, the entire dataset can be distorted—critical in high-precision applications like structural inspection or urban mapping.

Identifying Common Errors in Point Cloud Analysis
Uneven Point Density and Poor Data Quality
Point density is akin to image resolution. Low density may miss critical details like sharp edges or small objects, while overly dense data inflates file sizes, increases computational demands, and slows processing.Environmental factors like rain, fog, or reflective surfaces introduce noise and outliers, distorting the object’s true shape.
Solution: Apply preprocessing filters to remove outliers and reduce noise. Use strategic downsampling to balance detail and computational efficiency per task.
Inaccurate Geometric Segmentation
Segmentation divides the point cloud into geometrically or functionally meaningful clusters—like separating roads from sidewalks, or buildings from vegetation. Algorithms often struggle in complex scenes with shadows, occlusions, or irregular geometries, leading to incorrect groupings or over-segmentation.
Example: An autonomous vehicle may group a traffic sign with a nearby tree canopy, misidentifying both.
Solution: Use deep learning–based segmentation models. Incorporate sensor fusion (e.g., LiDAR + camera data) to provide context and improve accuracy.
Using Inappropriate Algorithms for Specific Tasks
No single algorithm works for all point cloud tasks. An algorithm optimized for road surface defect detection won’t work well for analyzing forest biomass.
A common mistake is applying general-purpose methods to specialized problems, which reduces performance and misinterprets data features.
Solution: Clearly define task requirements. Is real-time processing needed? Is the environment indoor or outdoor? What level of precision is required? Based on this, test algorithms on representative datasets before full deployment.
Misclassification in Semantic Segmentation
Semantic segmentation assigns meaningful labels to each point (e.g., “road”, “building”, “pedestrian”). Even advanced AI models can fail—objects close in space but different in meaning (like a person leaning against a wall) are easy to misclassify without enough context.
In high-stakes use cases like autonomous vehicles, such misclassifications can have serious consequences.
Solution: Train models on large, diverse, and well-labeled datasets. Continue using sensor fusion to provide additional context and boost model understanding.

Core Challenge: Risks in Data Labeling
Machine learning model performance directly depends on training data quality. Point cloud labeling faces three main risks:
- Label accuracy: Inconsistent or incorrect labels introduce noise, reducing model generalizability.
- Ambiguous data: Sparse, occluded, or noisy regions are hard to label and prone to errors.
- Dataset consistency: Without clear labeling protocols, datasets created by multiple people lack uniformity.
Solution: Establish a strict labeling workflow, including QA steps, labeler training, and AI-assisted labeling tools to speed up processes and ensure consistency.
You can try Coral Mountain Data which provides LiDAR and 3D data labeling solutions that help automate, review and validate data faster and more efficiently.
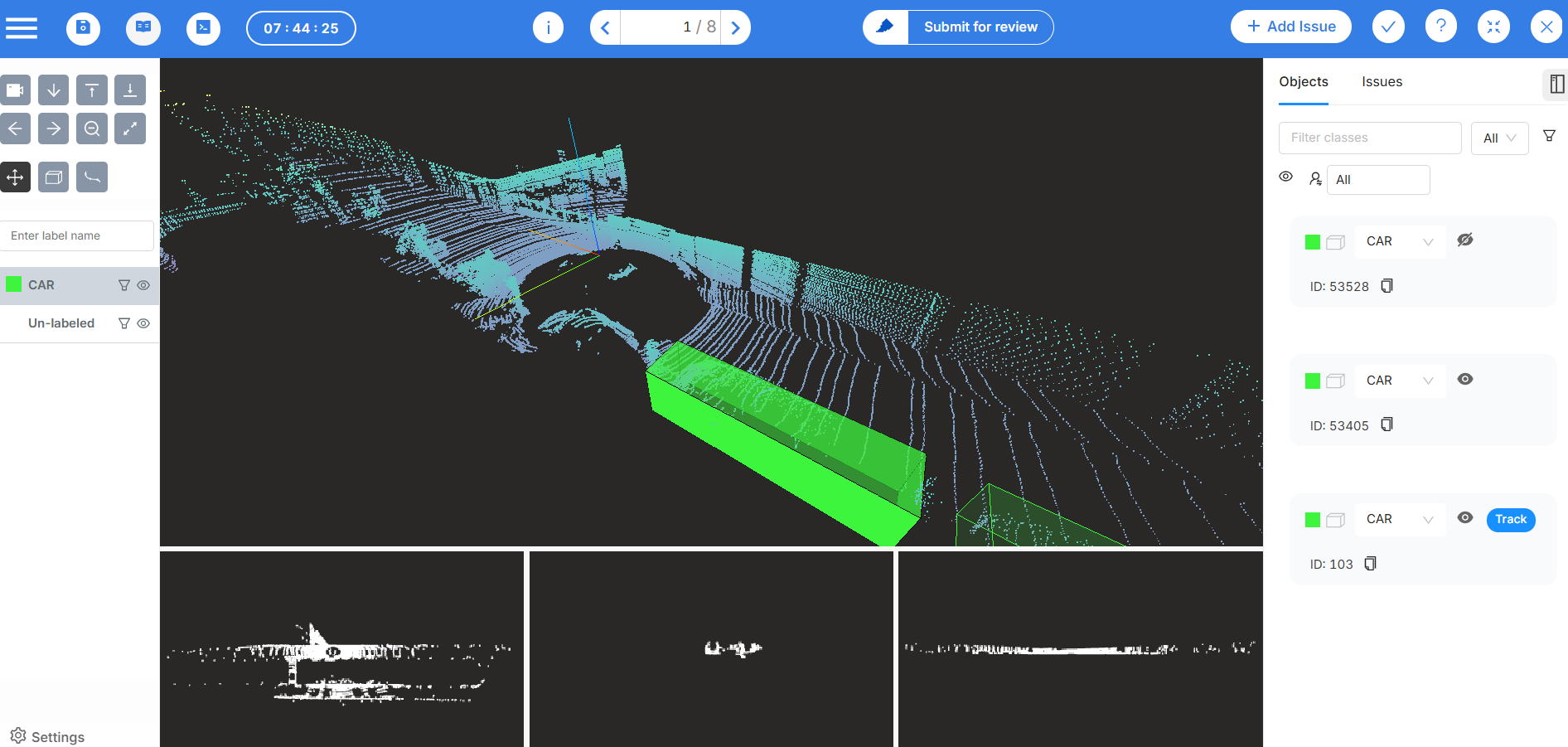
A Technical Framework for Optimized Processing
All the above challenges can be addressed through a systematic approach:
Rigorous Preprocessing and Smart Algorithm Selection
Begin with robust preprocessing—filter out outliers, denoise, and adjust point density. Then, choose the right algorithm for each stage: segmentation, feature extraction, modeling.
A hybrid approach often works best—use rule-based algorithms to detect large planes (like the ground), then neural networks for more complex object classification.
Leverage Sensor Power and Data Fusion
Sensor selection matters. Modern LiDAR systems offer high precision and multiple return capabilities. Regular calibration is essential to avoid systematic errors.
Fuse LiDAR with cameras, IMUs, and GNSS systems to create rich, multimodal data streams, significantly improving analytical accuracy.
Use Advanced Labeling Tools
To address manual labeling issues, adopt intelligent labeling platforms. Features like semi-automatic annotation, motion interpolation between frames, and QA dashboards transform labeling from a bottleneck into an efficient pipeline step.
Conclusion
Point cloud analysis is a foundational technology unlocking vast potential in digitizing and interacting with the real world—from autonomous vehicles and smart construction to virtual reality.
Yet, the value of this technology hinges entirely on data accuracy and integrity. As applications grow more complex and mission-critical, our processing approach must evolve in sophistication and rigor.
By identifying common pitfalls and adopting a structured methodology, we can harness the full power of this technology. In a world increasingly shaped by digital environments, the accuracy of each data point will determine the reliability of the entire system.
Coral Mountain Data is a company that provides high-quality data annotation services for artificial intelligence (AI) and machine learning (ML) models, helping to deliver high-quality input datasets and enhance model performance.