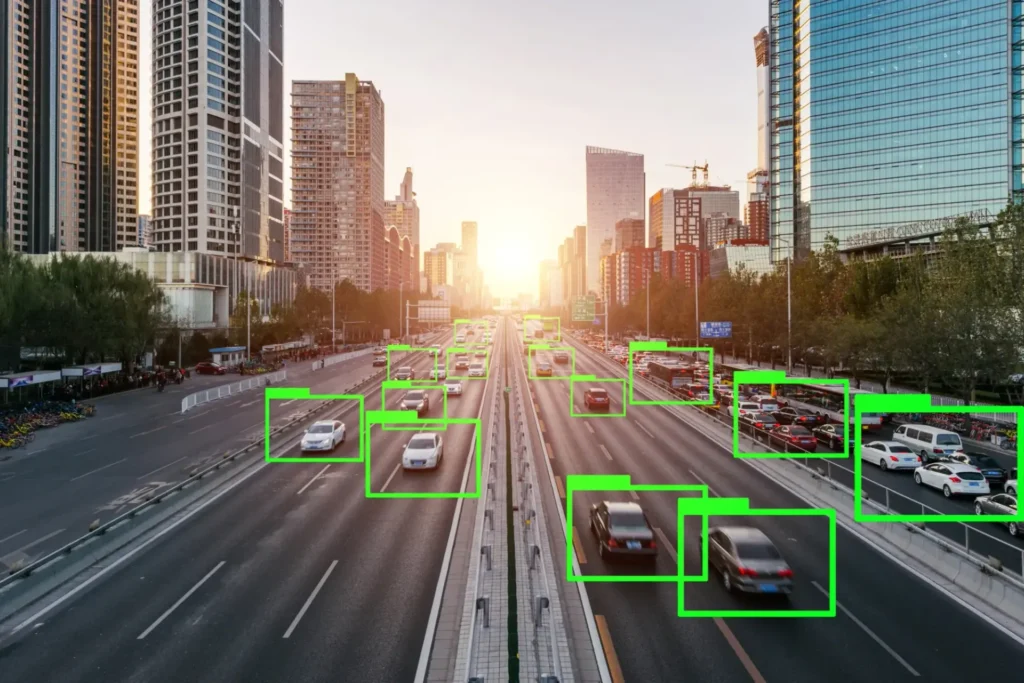
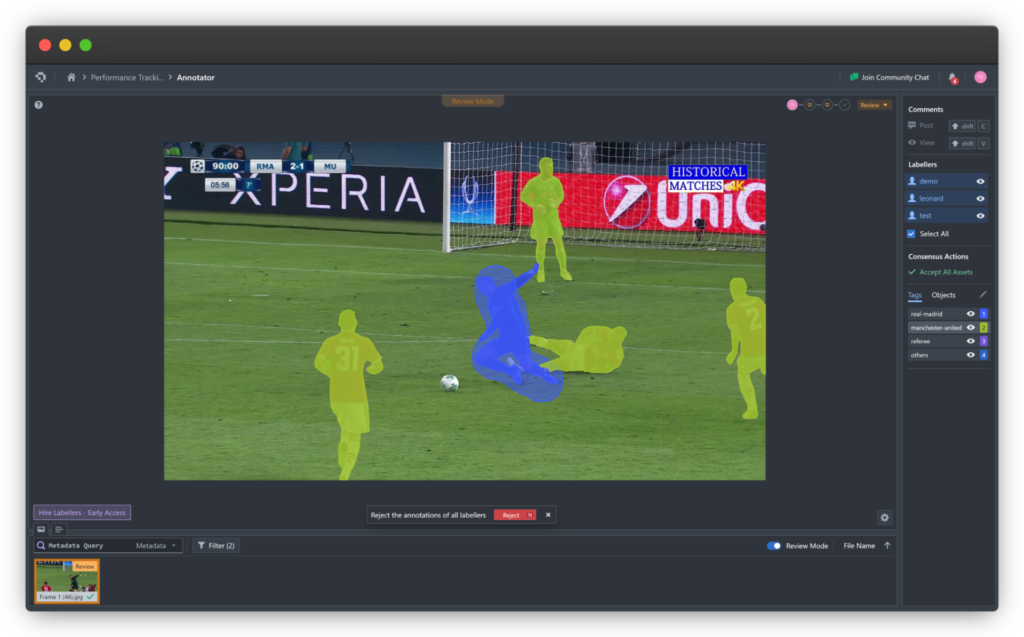
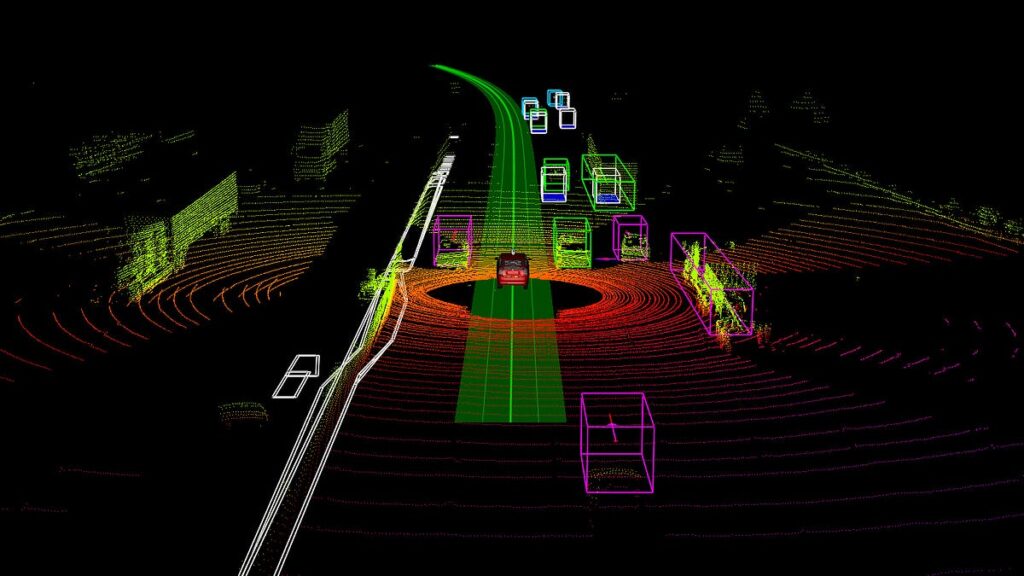
In the ecosystem of Artificial Intelligence (AI) and Machine Learning (ML) development, data labeling tools play a foundational infrastructure role. They serve as the bridge that transforms raw data into structured training datasets — the core assets that enable supervised learning models to recognize patterns, make predictions, and perform complex tasks.
This article offers a comprehensive analysis of data labeling, from fundamental concepts and standard processes to technical challenges and emerging technological trends shaping the future of this field.
Definition and Core Role of Data Labeling
At its core, data labeling is the process of annotating or tagging raw data (text, images, video, audio) with metadata to provide context for machine learning algorithms. This process generates the “ground truth” — a set of examples from which the model learns to generalize and make decisions on unseen data.
The importance of labeling lies in the direct relationship between label quality and model performance. Accurately and consistently labeled data is a prerequisite for effective model training, enabling high accuracy in real-world deployment. Conversely, poor or erroneous labels introduce “noise” into the training process, leading to inaccurate predictions and reduced system reliability.
In domains requiring high levels of safety and precision — such as healthcare, autonomous vehicles, and finance — the quality of labeled data is not only critical for business performance but also a key factor in ensuring safety and ethical compliance.

Classification of Data Labeling Methods
Depending on the data type and model objectives, labeling methods are divided into several specialized categories:
A. Text Annotation
Used to train Natural Language Processing (NLP) models:
- Named Entity Recognition (NER): Identifying and classifying entities like names, organizations, locations, dates.
- Sentiment Analysis: Labeling text segments according to emotional tone (e.g., positive, negative, neutral).
- Part-of-Speech (PoS) Tagging: Assigning grammatical roles to words (noun, verb, adjective), forming the basis for deeper linguistic analysis.
B. Image Annotation
Fundamental for Computer Vision models:
- Object Detection: Using bounding boxes to identify the location and category of each object in an image.
- Image Segmentation: Pixel-level labeling to divide the image into distinct regions representing different objects.
Image Classification: Assigning a single label to the entire image to define its overall theme (e.g., “beach scene”, “night cityscape”).
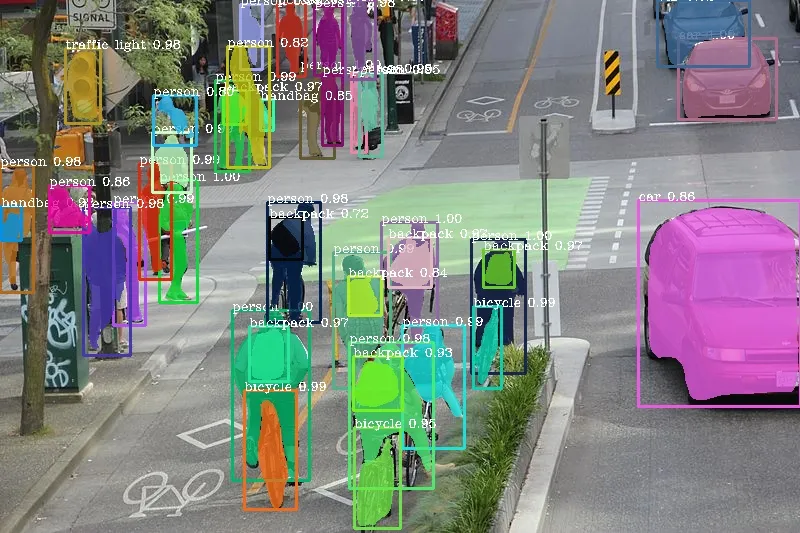

video caption
Standard Data Labeling Workflow
An effective data labeling project typically follows a structured workflow:
- Data Collection & Preprocessing: Begins with sourcing relevant raw data for the task. Data is then cleaned to remove errors, irrelevant information, and inconsistencies, ensuring high-quality input.
- Guideline Creation & Tool Selection: A comprehensive set of labeling instructions must be created to ensure consistency. The right annotation platform is also selected to optimize the workflow.
Execution & Quality Assurance (QA): Labeling is conducted according to the guidelines, with integrated QA mechanisms (e.g., peer reviews, automated checks) used to identify and fix errors, ensuring label accuracy.
Technical & Operational Challenges
Several inherent challenges affect the data labeling process:
- Maintaining Data Quality: Ensuring label accuracy across large datasets is a major challenge. Subjective annotator errors and ambiguous data can degrade overall quality.
- Consistency Across Annotators: With multiple annotators, maintaining consistent interpretation and application of labels is difficult.
- Scaling & Efficiency: Manual labeling is time-consuming and costly. As data volume grows, balancing speed, cost, and accuracy becomes a complex optimization problem.
Privacy & Ethics: Handling sensitive data (e.g., personal information, medical records) requires strict adherence to privacy laws and ethical standards to protect users.
Advanced Features in Modern Labeling Tools
To address these challenges, modern annotation platforms integrate several advanced capabilities:
- Semi-Automated Segmentation (Magic Segment): Built-in AI algorithms automatically propose object boundaries. Annotators only need to refine them, significantly reducing time while maintaining accuracy.
- 3D Data Support (LiDAR): Specialized tools now support direct annotation on 3D point clouds, essential for applications such as autonomous vehicles, robotics, and mapping.
- Integrated QA Mechanisms:
- Multi-Annotator Support: Enables comparison and resolution of label conflicts to reach consensus.
- Honeypot Technique: Inserts pre-labeled data into the workflow to assess annotator performance in real time.
Error Management System: Provides a dashboard for reviewers to track, report, and request corrections of inconsistent or problematic labels.
Future Trends in Data Labeling
The data labeling space is rapidly evolving, driven by these key trends:
- Automation & Pre-labeling: AI models are increasingly used to perform initial labeling, with humans acting as reviewers. This approach speeds up the process and boosts efficiency.
- Active Learning: Rather than labeling all data, the model actively selects the most ambiguous or “uncertain” data points. Labeling these samples improves model performance with less data.
- Federated Learning: Models are trained across decentralized data sets without data movement. This approach solves privacy concerns and enables cross-organization collaboration without sharing sensitive data.
Conclusion
Data labeling tools are a critical component of the AI value chain. Understanding labeling methods, workflows, challenges, and tech trends enables organizations to make strategic decisions and optimize their AI development pipeline. Choosing the right tools and best practices directly impacts model training efficiency, leading to accurate and trustworthy AI systems.
To ensure high-quality input data and maximize model performance, organizations can partner with professional data labeling service providers. Coral Mountain Data is one such company delivering high-quality data labeling services for AI and ML models, helping clients build a strong data foundation to enhance the performance of their applications.aa