Explore the intersecting worlds of Data Annotation and MLOps, and learn how they work together to build high-quality machine learning pipelines.

Annotated data is a key requirement for Machine Learning models to learn to predict.
Annotated data is essential for enabling Machine Learning models to learn and make predictions.
While machine learning has transformed countless industries—from healthcare to self-driving vehicles—its success hinges on the availability of well-labeled training data. Data annotation, the process of labeling raw data for algorithm training, is a foundational step toward building accurate models. To make this process scalable and consistent, data annotation tools have emerged as indispensable resources.
At the same time, MLOps (Machine Learning Operations) focuses on managing the entire lifecycle of machine learning models—from development to deployment and beyond. In the sections below, we explore how these two domains complement each other.
How Does Data Annotation Work?
Data annotation involves labeling datasets so that machine learning models can interpret them. It begins with collecting raw data—such as text, images, audio, videos, or 3D point clouds—and assigning structured labels that provide context for the model.
The process typically starts with establishing annotation guidelines, which ensure annotators follow consistent rules. For example, image annotation guidelines may define which objects should be labeled, how to handle overlaps, or how to treat ambiguous cases.
Once guidelines are in place, the actual labeling begins. Depending on complexity, this could range from simple tagging to defining cuboids or pixel-level segmentation in 3D datasets. Annotation platforms often include features like automation assistance and validation tools to streamline repetitive work and reduce errors.
After labeling, a Quality Assurance (QA) phase ensures accuracy and consistency. QA may involve manual review, automated checks, or re-annotation where needed. Even minor mistakes can degrade model performance, making this step crucial.
Finally, the labeled data is formatted and prepared for training—often split into training, validation, and test sets.
The Need for Data Annotation
Machine learning models rely on large volumes of high-quality labeled data. Whether it’s bounding boxes for object detection or sentiment labels in NLP, annotated datasets act as the ground truth that drives model learning.
However, manual annotation is time-intensive and prone to inconsistency, especially as datasets grow. This is where data annotation tools provide tremendous value by offering structure, automation, and collaboration capabilities.
Data Annotation Tools: Features and Capabilities

Our Magic select tool allows users to segment complex objects with just a few clicks.
Image annotation interface on the Coral Mountain Annotation platform
Modern annotation tools provide a range of features designed to make labeling more efficient:
Annotation Interfaces: Intuitive UIs support drawing tools like bounding boxes, polygons, and mask regions—with customization and shortcuts for speed.
Collaboration and Workflow Management: Teams can assign tasks, track progress, and resolve conflicts. Built-in workflows help move data through review stages.
Quality Control and Review: Supervisors can approve or correct labels, leave feedback, and enforce consistency across annotators.
Automation and AI Assistance: Many tools integrate pre-trained models to auto-suggest labels or detect errors, helping annotators focus on more complex cases.
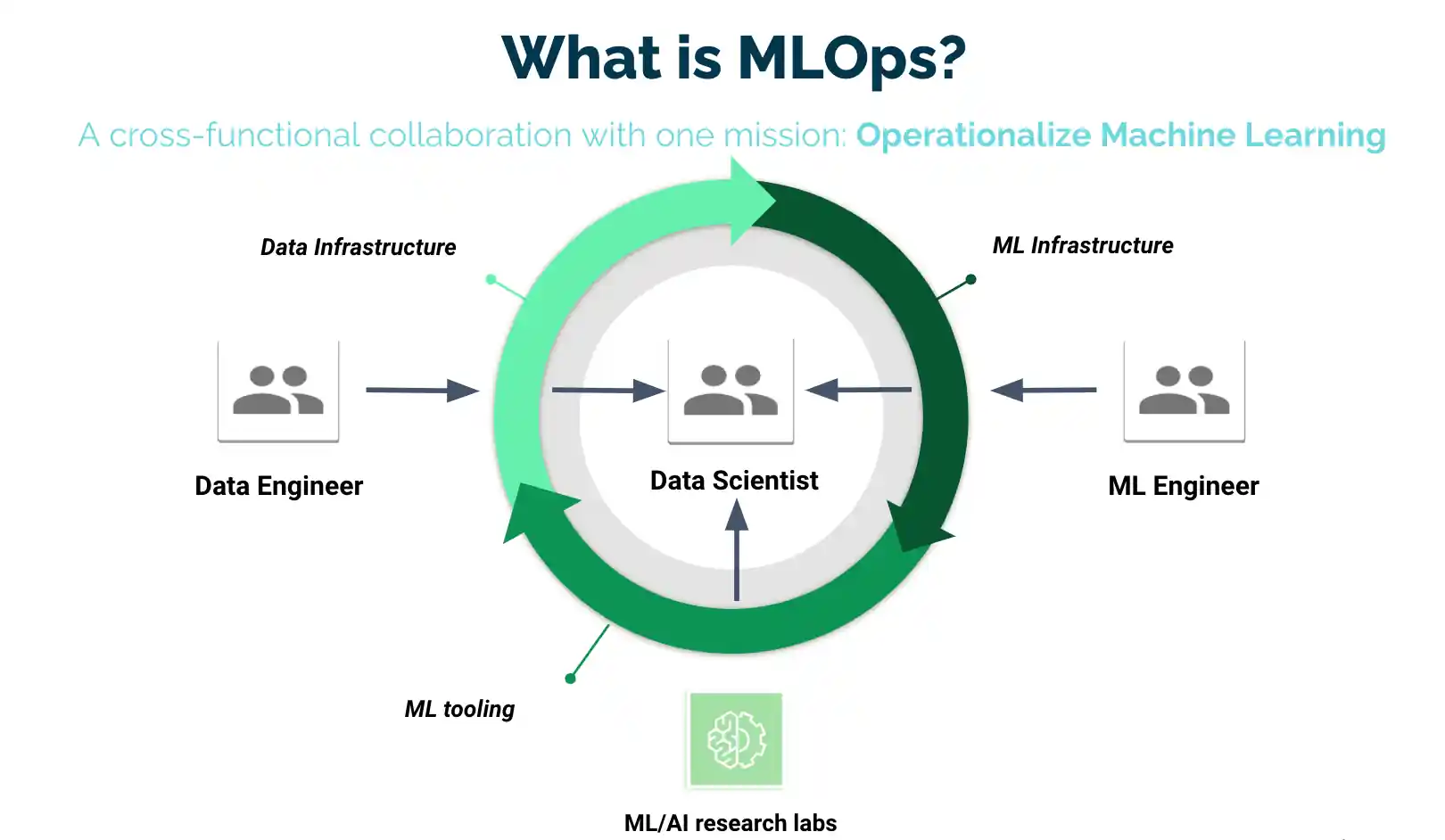
What is MLOps?
While annotation tools are essential, they represent just one part of the broader MLOps (Machine Learning Operations) ecosystem. MLOps encompasses the tools and practices required to manage ML models from data preparation to deployment and monitoring.
It combines principles from DevOps with the unique needs of machine learning systems. Rather than just creating a model, MLOps ensures that it can scale, adapt, and remain reliable in real-world environments.
The MLOps pipeline
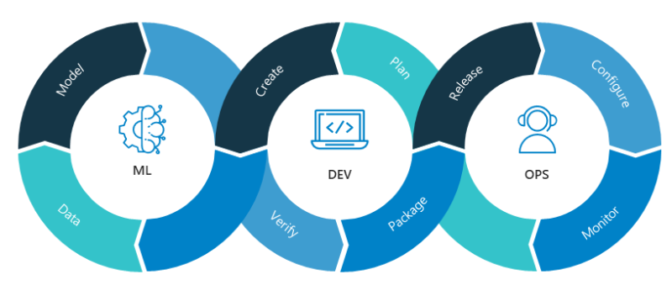
A typical MLOps lifecycle (Source: NVIDIA blogs)
A typical MLOps lifecycle includes the following stages:
Data Preparation: After data is collected and annotated, it is cleaned, transformed, and sometimes augmented for model readiness.
Model Development and Training: Teams use frameworks like TensorFlow, PyTorch, or scikit-learn, alongside platforms such as MLflow and DVC for experiment tracking and reproducibility.
Deployment and Serving: Models are packaged (often with Docker/Kubernetes) and deployed with serving tools like TensorFlow Serving or Seldon Core.
Monitoring and Maintenance: Performance must be continuously tracked using tools like Prometheus or Grafana. CI/CD pipelines help automate retraining and redeployment.
Feedback Loop: Real-world input reveals model weaknesses. This feedback is used to refine data, improve annotations, or retrain models—closing the loop.
The future of MLOps and Data Annotation tools
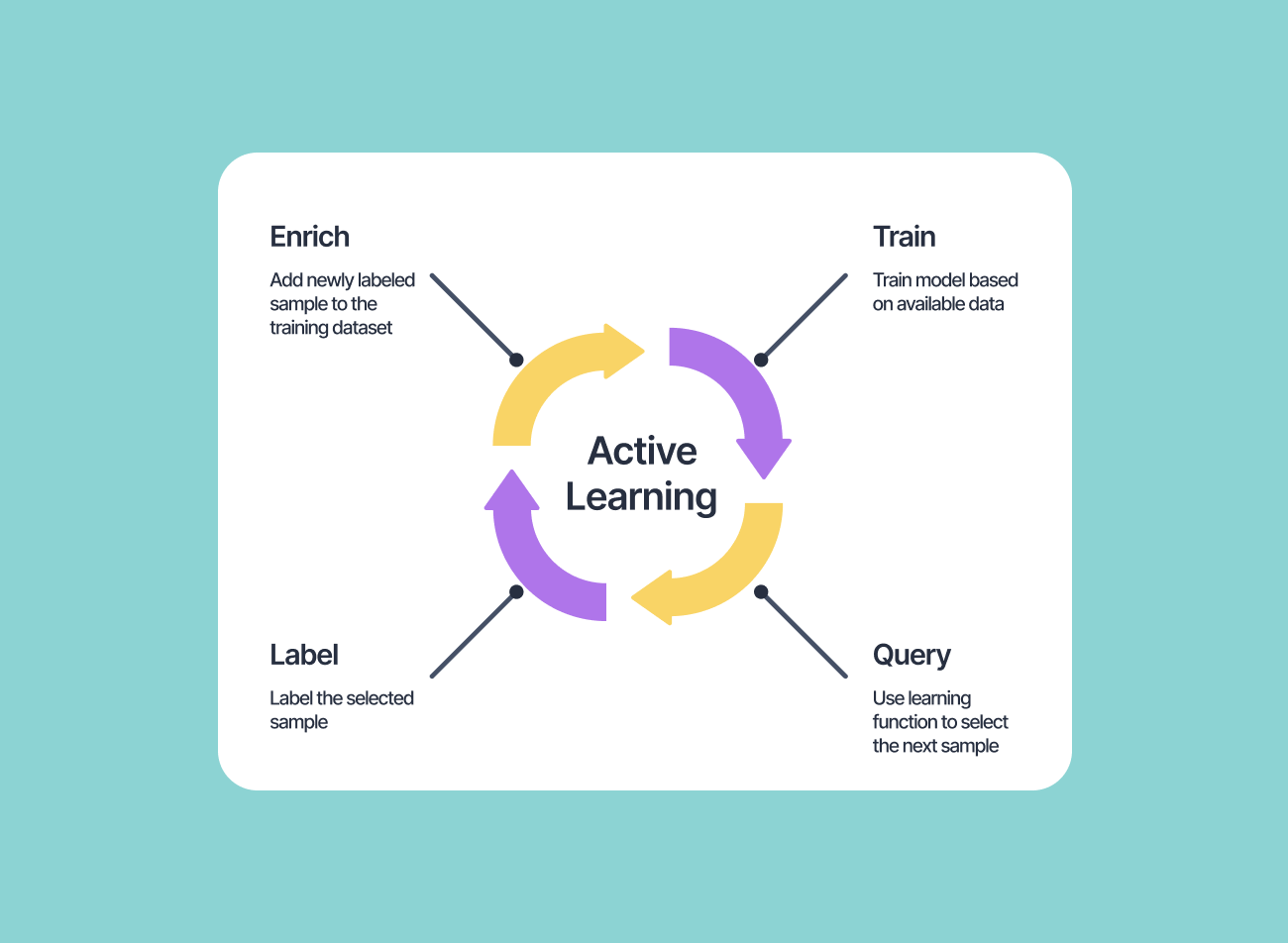
A typical Active Learning pipeline
As AI systems evolve, both annotation platforms and MLOps practices will advance in parallel. Key trends include:
Active Learning and Semi-Supervised Learning: Annotation tools will integrate smarter sampling, allowing human labelers to focus only on high-impact or uncertain cases.
Explainability and Interpretability: As ML adoption grows in sensitive domains, transparency becomes critical. Future tools will embed explainability features by default.
Automated Data Labeling: Techniques such as weak supervision and transfer learning will increasingly reduce manual annotation workloads, with annotation platforms orchestrating the process.
Conclusion
Data annotation tools are foundational to building reliable machine learning models, enabling scalable and accurate dataset creation. MLOps then takes these models through the full lifecycle of deployment, monitoring, and improvement.
Together, data annotation and MLOps form the backbone of modern AI infrastructure—ensuring not just model accuracy, but long-term reliability and adaptability.
As these fields continue to converge, the future of AI systems will become even more automated, transparent, and efficient.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….