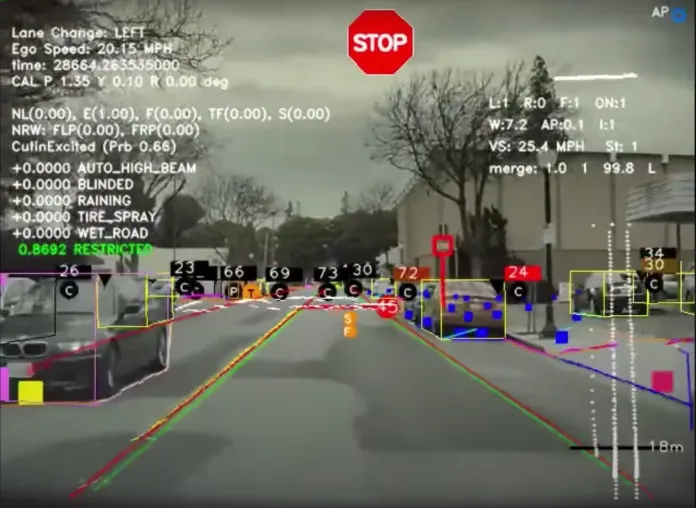
Tesla stands apart from other automakers thanks to its global fleet of constantly connected vehicles, each one continuously collecting real-world driving data. Every second of footage and every sensor reading has the potential to improve Tesla’s AI models. However, manually labeling all of that data would be prohibitively expensive and time-consuming. To solve this, Tesla relies heavily on Active Learning — a strategy that allows its machine learning systems to decide for themselves which data is most valuable for labeling.
Rather than treating every frame of data equally, Active Learning enables Tesla’s models to identify the moments that matter most — scenarios where the system is uncertain or encounters something unusual. Those edge cases are automatically flagged and uploaded for human review. Once labeled, they are fed back into the training pipeline. This approach allows Tesla to dramatically scale its intelligence while minimizing manual data processing.
What Is Active Learning?
Modern deep learning systems typically rely on vast amounts of labeled data. Yet data annotation is one of the most labor-intensive and expensive parts of the machine learning lifecycle, often consuming up to 80% of total project effort. In specialized areas like medical imaging or autonomous driving, labeling requires expert knowledge, which pushes costs even higher.
Active Learning helps reduce that burden by allowing the model to choose which samples to learn from. Instead of labeling everything upfront, the system selects only the most informative examples — those that challenge the model or expose gaps in its understanding. By focusing effort on the most valuable data, the model learns faster and with less supervision.
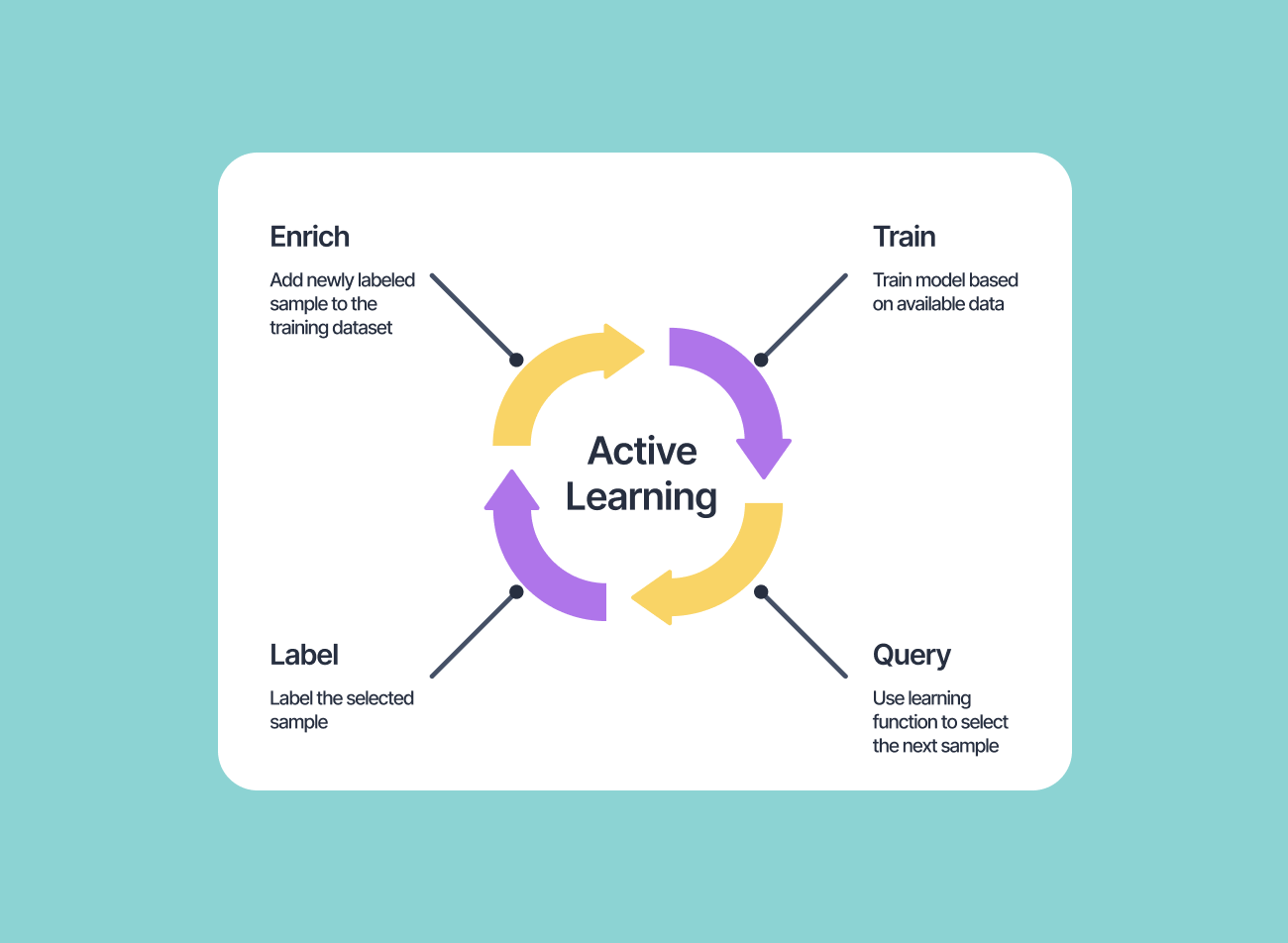
How Tesla Implements Active Learning
In an Active Learning workflow, the process typically unfolds in cycles. A small batch of data is labeled and used to train an initial model. That model is then applied to large pools of unlabeled data, and any samples that generate high uncertainty or model disagreement are selected for labeling next. Those newly annotated samples are added to the training set, the model is retrained, and the cycle repeats. This continues either until the desired performance level is reached or the labeling budget is met.
Tesla has adapted this framework across several key areas of its business — most notably in autonomous driving, battery optimization, and manufacturing.
Autonomous Driving Technology
Autonomous driving is where Tesla’s use of Active Learning is most visible. The Autopilot and Full Self-Driving (FSD) systems rely on a combination of cameras, radar, and ultrasonic sensors to understand the environment. These sensors generate massive volumes of data, but sending everything back to Tesla’s servers would be inefficient.
Instead, Tesla uses an onboard Active Learning system that selectively identifies edge cases — rare or confusing scenarios that the model cannot confidently interpret. These situations are flagged and sent back to headquarters for human annotation. For example, if the vision model struggles to distinguish between a plastic bag and a small animal on the road, that clip is prioritized for review.
Tesla combines two core Active Learning strategies in this process: uncertainty sampling, which captures cases where the model is least confident, and query-by-committee, which compares predictions from multiple models and selects samples where there is disagreement. This ensures that only the most meaningful failures or ambiguities are escalated for labeling.

Battery Management

Active Learning is also applied to Tesla’s battery management systems. Battery performance can vary based on temperature, charging habits, or driver behavior. Rather than training on generic datasets, Tesla allows its models to flag cases where battery behavior deviates from expected patterns — such as rapid degradation or abnormal heat levels.
Only these anomalous cases are prioritized for deeper analysis and labeling. This targeted approach helps Tesla improve charge balancing, thermal regulation, and lifespan prediction — all while minimizing data overhead. In practice, it enables smarter maintenance and more accurate range estimation without manually reviewing millions of routine battery logs.
Manufacturing Optimization
Within Tesla’s factories, computer vision systems monitor quality across processes like welding and painting. Just like in autonomous driving, Tesla does not stream endless footage of flawless parts. Instead, Active Learning filters out routine output and forwards only uncertain or potentially defective cases to human inspectors.
This streamlines quality control by focusing attention where it’s needed most. It also ensures that the inspection models continuously improve based on real-world production errors rather than synthetic training sets.
Conclusion
Tesla’s strength lies not only in the size of its data but in how intelligently it’s used. Active Learning gives Tesla a scalable way to improve its machine learning systems without drowning in raw information or ballooning annotation costs. By prioritizing the rare, ambiguous, or problematic moments, Tesla accelerates model improvement where it matters most.
While the company also leverages techniques like self-supervised and reinforcement learning, Active Learning remains one of the most practical and impactful tools in its AI toolkit. As more Teslas hit the road and more data flows into the system, these feedback loops only grow stronger — ensuring the fleet gets smarter with every mile.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….