Công cụ gán nhãn dữ liệu là yếu tố thiết yếu trong quá trình phát triển các mô hình học máy (ML) và trí tuệ nhân tạo (AI). Những công cụ này giúp tạo ra các bộ dữ liệu được gán nhãn – nền tảng quan trọng để huấn luyện mô hình nhằm đưa ra dự đoán chính xác và thực hiện các tác vụ phức tạp như nhận diện đối tượng, phân tích cảm xúc, v.v.
Gán nhãn dữ liệu là gì?
Gán nhãn dữ liệu là quá trình đánh dấu hoặc gắn thẻ cho dữ liệu để làm cho nó có thể hiểu được đối với các thuật toán học máy. Quá trình này biến dữ liệu thô thành định dạng có cấu trúc, giúp mô hình học được cách nhận diện mẫu và ra quyết định chính xác. Việc gán nhãn có thể áp dụng cho nhiều loại dữ liệu khác nhau như văn bản, hình ảnh, video, tùy theo mục đích đầu ra của mô hình AI.
Tại sao gán nhãn dữ liệu lại quan trọng?
Gán nhãn dữ liệu ảnh hưởng trực tiếp đến chất lượng và hiệu suất của các mô hình AI và học máy (ML). Dữ liệu được gán nhãn chính xác giúp mô hình học tốt hơn, dẫn đến kết quả khả quan hơn khi áp dụng trong thực tế. Ngược lại, dữ liệu sai lệch hoặc được gán nhãn kém có thể khiến mô hình đưa ra dự đoán sai, làm giảm độ tin cậy và hiệu quả.
Trong các lĩnh vực như chăm sóc sức khỏe, xe tự hành, và bán lẻ – nơi yêu cầu độ chính xác cao – gán nhãn dữ liệu đúng đóng vai trò then chốt trong việc đảm bảo an toàn, hiệu quả và sự hài lòng của khách hàng.
Ứng dụng thực tế của gán nhãn dữ liệu
Gán nhãn dữ liệu đóng vai trò then chốt trong nhiều ngành công nghiệp, giúp hiện thực hóa các ứng dụng AI tiên tiến:
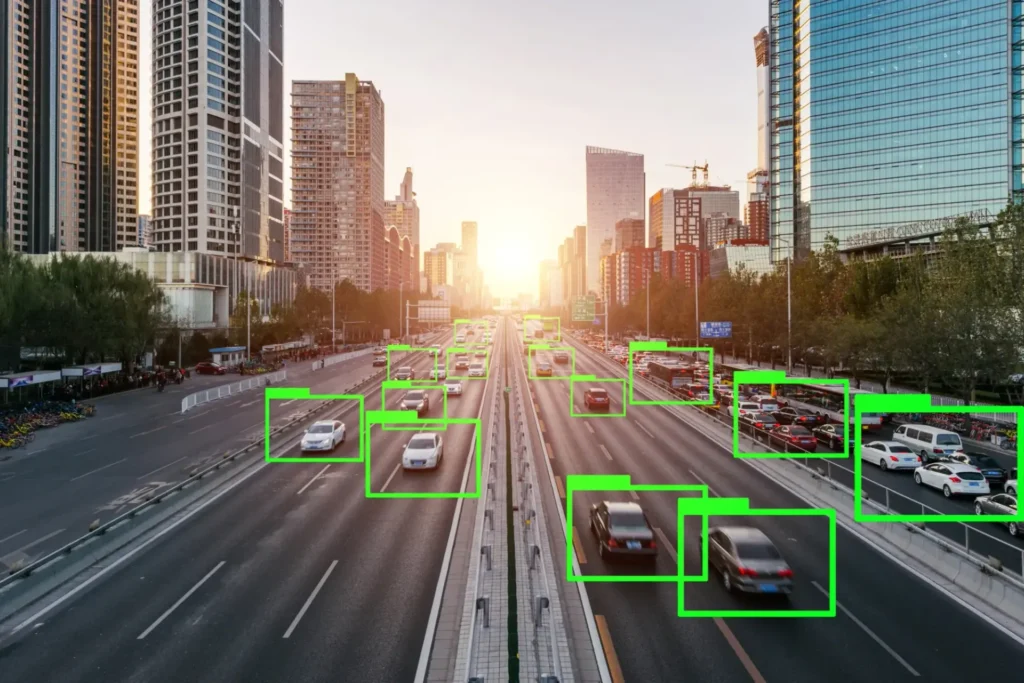
- Thị giác máy tính (Computer Vision): Hình ảnh và video được gán nhãn được sử dụng để huấn luyện mô hình nhận diện đối tượng, con người và môi trường — ứng dụng phổ biến trong an ninh, bán lẻ và y tế.
- Xử lý ngôn ngữ tự nhiên (NLP): Việc gán nhãn văn bản giúp nâng cao hiệu quả của các tác vụ như phân tích cảm xúc, dịch ngôn ngữ và chatbot bằng cách giúp mô hình hiểu được sắc thái của ngôn ngữ con người.
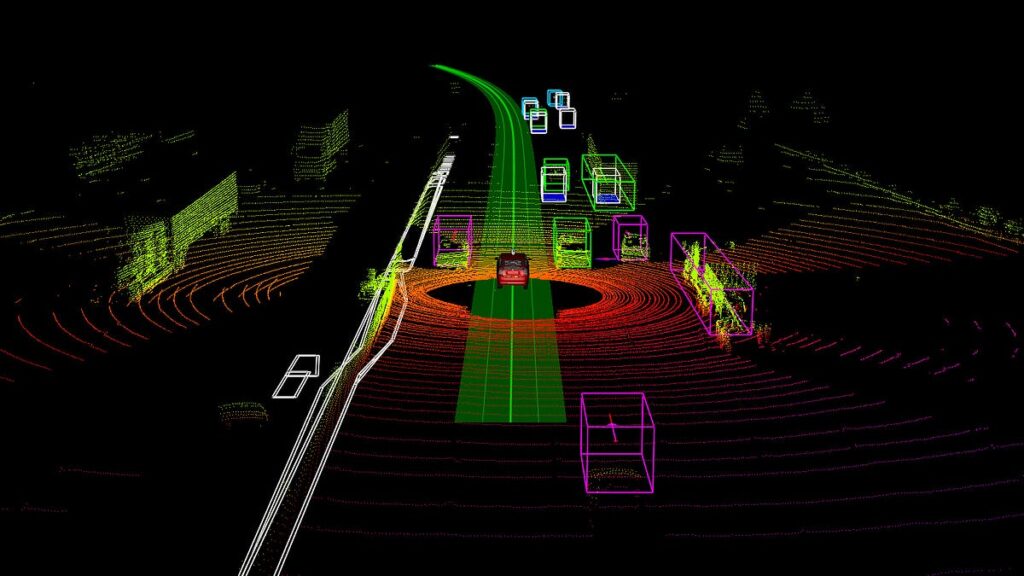
- Xe tự hành: Việc gán nhãn chính xác các đối tượng như người đi bộ, biển báo giao thông và các phương tiện khác là cực kỳ quan trọng để huấn luyện xe tự lái di chuyển một cách an toàn.

Các loại gán nhãn dữ liệu
Gán nhãn dữ liệu có nhiều hình thức khác nhau, phù hợp với từng loại tác vụ AI riêng biệt:
Gán nhãn văn bản (Text Annotation)
Liên quan đến việc đánh dấu hoặc gán nhãn các phần cụ thể trong văn bản để giúp các mô hình xử lý ngôn ngữ tự nhiên (NLP) hiểu được nội dung. Một số loại chính bao gồm:
- Nhận dạng thực thể có tên (Named Entity Recognition – NER): Xác định và phân loại các thực thể như tên người, ngày tháng, địa điểm.
- Phân tích cảm xúc (Sentiment Analysis): Gán nhãn văn bản theo cảm xúc tích cực, tiêu cực hoặc trung tính, giúp mô hình hiểu được ngữ cảnh cảm xúc.
- Gán nhãn từ loại (Part-of-Speech Tagging): Xác định vai trò ngữ pháp của từng từ (danh từ, động từ, tính từ,…), hỗ trợ phân tích ngôn ngữ.
Gán nhãn hình ảnh (Image Annotation)
Dùng để xác định và gán nhãn các đối tượng trong hình ảnh, giúp mô hình hiểu và xử lý dữ liệu thị giác.
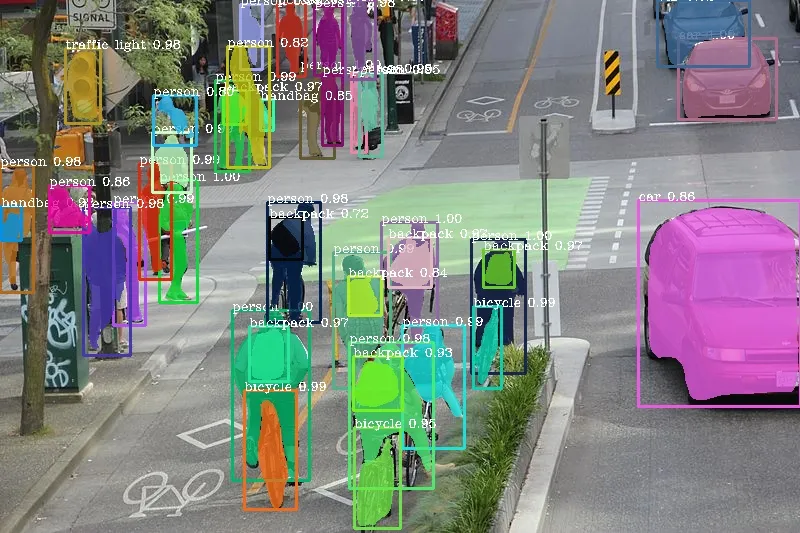
- Phát hiện đối tượng (Object Detection): Sử dụng các khung bao (bounding boxes) để đánh dấu vị trí của các đối tượng trong ảnh.
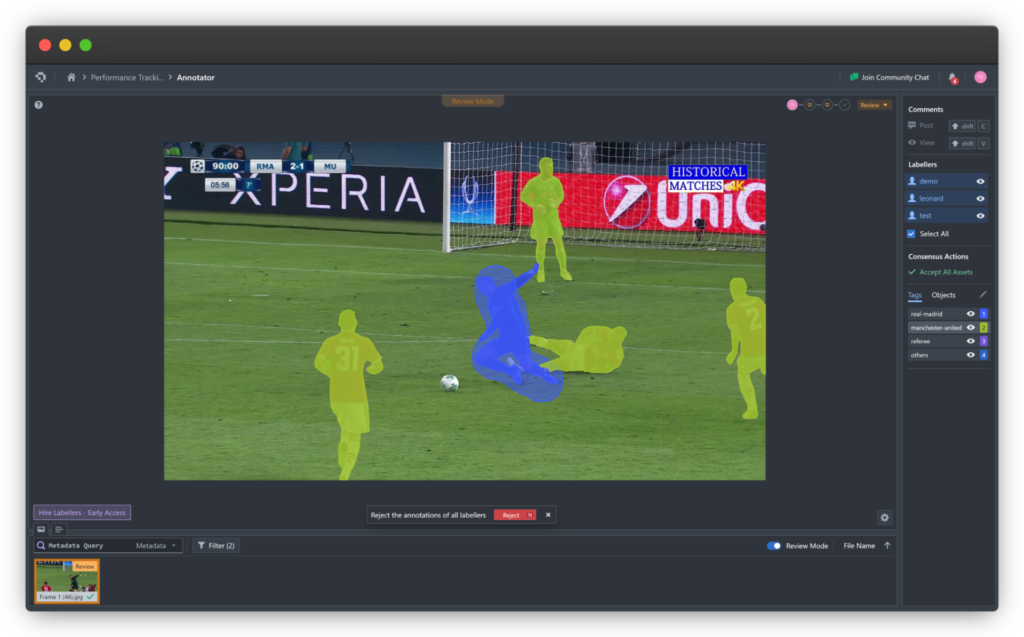
- Phân đoạn hình ảnh (Image Segmentation): Gán nhãn từng điểm ảnh (pixel) để mô hình phân biệt các vùng hoặc đối tượng khác nhau trong hình.
- Phân loại hình ảnh (Image Classification): Gán nhãn cho toàn bộ hình ảnh để xác định chủ đề hoặc loại đối tượng, ví dụ như phân biệt động vật hoặc phương tiện.
Chú thích Video (Video Annotation)
Đối với các tác vụ dựa trên video, việc chú thích bao gồm nhận dạng và theo dõi các đối tượng hoặc hành động xuyên suốt các khung hình.
-
Nhận dạng Hành động (Action Recognition): Gắn nhãn cho các hành động như đi bộ, nhảy, hoặc lái xe trong các chuỗi video.
-
Theo dõi Đối tượng (Object Tracking): Theo dõi các đối tượng qua nhiều khung hình trong một video, đóng vai trò then chốt cho các ứng dụng như lái xe tự hành.
-
Nhận dạng Khuôn mặt (Facial Recognition): Gắn nhãn và nhận dạng các khuôn mặt trong luồng video, giúp nâng cao các hệ thống an ninh và giám sát.

Quy trình gán nhãn dữ liệu (Data Annotation Process)
Gán nhãn dữ liệu là một quy trình có cấu trúc, gồm nhiều bước như sau:
- Thu thập dữ liệu
Bước đầu tiên là thu thập các dữ liệu liên quan. Chất lượng dữ liệu rất quan trọng, vì bộ dữ liệu được tổ chức tốt sẽ giúp quá trình huấn luyện mô hình hiệu quả hơn. - Làm sạch và tiền xử lý dữ liệu
Trước khi tiến hành gán nhãn, dữ liệu cần được làm sạch và xử lý sơ bộ nhằm loại bỏ lỗi, sự không nhất quán hoặc thông tin không liên quan. Bước này đảm bảo rằng chỉ dữ liệu chất lượng cao mới được đưa vào quy trình gán nhãn. - Hướng dẫn gán nhãn và kiểm soát chất lượng
Để đảm bảo việc gán nhãn nhất quán và chính xác, cần xây dựng các hướng dẫn rõ ràng. Những hướng dẫn này phải quy định cách dữ liệu được gán nhãn, đồng thời thiết lập cơ chế kiểm soát chất lượng nhằm đảm bảo các nhãn đạt chuẩn yêu cầu. - Công cụ và nền tảng gán nhãn
Các công cụ gán nhãn dữ liệu giúp tối ưu hóa quy trình bằng cách cung cấp các tính năng như gợi ý gán nhãn trước (pre-annotation), kiểm soát chất lượng và hỗ trợ làm việc nhóm.
Những thách thức trong quá trình gán nhãn dữ liệu
Mặc dù đóng vai trò quan trọng, quá trình gán nhãn dữ liệu cũng gặp phải nhiều thách thức, bao gồm:
- Vấn đề về chất lượng dữ liệu
Đảm bảo các nhãn được gán chính xác và không có sai sót là một thách thức lớn. Việc gán nhãn kém chất lượng có thể làm giảm hiệu suất của mô hình, do đó cần có các quy trình kiểm soát chất lượng nghiêm ngặt. - Tính nhất quán trong việc gán nhãn
Trong các bộ dữ liệu lớn, việc duy trì tính nhất quán giữa các điểm dữ liệu hoặc giữa nhiều người gán nhãn khác nhau là điều không dễ dàng. Các công cụ có hệ thống đánh giá và phản hồi giúp cải thiện vấn đề này. - Khả năng mở rộng và hiệu quả
Khi quy mô dữ liệu tăng lên, việc gán nhãn thủ công trở nên tốn thời gian và chi phí. Việc cân bằng giữa tốc độ và độ chính xác trong quá trình mở rộng quy mô gán nhãn vẫn là một thách thức đối với nhiều tổ chức. - Mối quan tâm về quyền riêng tư và đạo đức
Quyền riêng tư dữ liệu ngày càng được quan tâm, đặc biệt khi xử lý các thông tin nhạy cảm như hồ sơ y tế hoặc dữ liệu cá nhân. Cần tuân thủ các hướng dẫn đạo đức để đảm bảo dữ liệu được xử lý một cách có trách nhiệm.
Tiêu điểm: Công cụ Gán nhãn của Chúng Tôi
Công cụ gán nhãn của chúng tôi được thiết kế nhằm đơn giản hóa và nâng cao hiệu quả quá trình gán nhãn dữ liệu. Dưới đây là những điểm nổi bật tạo nên sự khác biệt:
Magic Segment
Tính năng phân đoạn tự động Magic Segment giúp đơn giản hóa việc gán nhãn cho những hình ảnh phức tạp bằng cách tạo ra các mặt nạ phân đoạn chính xác. Tính năng này giúp tiết kiệm đáng kể thời gian gán nhãn thủ công mà vẫn đảm bảo độ chính xác cao.
Hỗ trợ dữ liệu Lidar
Với khả năng hỗ trợ dữ liệu lidar một cách trực tiếp, công cụ của chúng tôi cho phép gán nhãn chính xác các đám mây điểm 3D – lý tưởng cho các ứng dụng như xe tự lái và robot.
Tính năng Đảm bảo Chất lượng
Để đảm bảo chất lượng gán nhãn ở mức cao nhất, chúng tôi cung cấp các tính năng sau (bạn có thể đọc thêm chi tiết tại đây):
- Thiết lập nhiều người gán nhãn: Cho phép nhiều người cùng làm việc trên một bộ dữ liệu, hỗ trợ việc cộng tác và so sánh kết quả.
- Cơ chế Honeypot: Chèn các điểm dữ liệu đã được gán nhãn sẵn để theo dõi độ chính xác của người gán nhãn theo thời gian thực.
- Hệ thống quản lý lỗi: Giúp theo dõi và xử lý hiệu quả các điểm gán nhãn không nhất quán hoặc có vấn đề.
Xu hướng tương lai trong gán nhãn dữ liệu
Khi trí tuệ nhân tạo (AI) không ngừng phát triển, nhiều xu hướng mới đang định hình tương lai của quá trình gán nhãn dữ liệu.
1. Kỹ thuật gán nhãn tự động
Việc tự động hóa đang ngày càng phổ biến trong lĩnh vực gán nhãn dữ liệu, với các công cụ được hỗ trợ bởi AI có thể thực hiện gán nhãn trước. Những kỹ thuật này giúp giảm bớt khối lượng công việc cho con người, tăng tốc độ và hiệu quả xử lý dữ liệu.
2. Học chủ động (Active Learning)
Học chủ động cho phép mô hình lựa chọn những điểm dữ liệu cần được gán nhãn dựa trên mức độ tự tin của nó. Bằng cách tập trung vào các trường hợp không chắc chắn hoặc mơ hồ, mô hình có thể cải thiện hiệu suất chỉ với số lượng ít hơn các ví dụ được gán nhãn.
3. Học liên kết phân tán (Federated Learning)
Học liên kết phân tán là quá trình huấn luyện mô hình trên nhiều nguồn dữ liệu phân tán mà không cần chia sẻ dữ liệu thực tế. Cách tiếp cận này giúp tăng cường quyền riêng tư, đồng thời tạo điều kiện hợp tác giữa các tổ chức – trở thành một xu hướng mới nổi trong gán nhãn dữ liệu.
Các yếu tố bổ sung cần cân nhắc
Khi triển khai các dự án gán nhãn dữ liệu, điều quan trọng là phải điều chỉnh phương pháp phù hợp với yêu cầu cụ thể của mô hình AI. Nên tích hợp các nghiên cứu điển hình (case study) để minh họa giá trị của dữ liệu được gán nhãn chất lượng cao, đồng thời lưu ý đến mức độ hiểu biết kỹ thuật của đối tượng mục tiêu. Những mẹo hữu ích như xây dựng hướng dẫn gán nhãn rõ ràng và áp dụng các biện pháp kiểm soát chất lượng sẽ góp phần nâng cao hiệu quả dự án.
Kết luận
Các công cụ gán nhãn dữ liệu là yếu tố không thể thiếu trong việc phát triển các mô hình AI mạnh mẽ. Bằng cách hiểu rõ các loại gán nhãn, thách thức đi kèm và các xu hướng mới nhất, các bên liên quan có thể đưa ra quyết định sáng suốt để tối ưu hóa quy trình gán nhãn. Việc lựa chọn đúng công cụ và tuân theo các phương pháp tốt nhất sẽ giúp mô hình được huấn luyện hiệu quả, dẫn đến các dự đoán chính xác và đáng tin cậy. Coral Mountain Data là công ty cung cấp dịch vụ gán nhãn dữ liệu chất lượng cao cho các mô hình trí thông minh nhân tạo (AI) và học máy (ML) giúp cung cấp nguồn dữ liệu đầu vào chất lượng cao, làm gia tăng hiệu năng các mô hình.
Coral Mountain Data là công ty cung cấp dịch vụ gán nhãn dữ liệu chất lượng cao cho các mô hình trí thông minh nhân tạo (AI) và học máy (ML) giúp cung cấp nguồn dữ liệu đầu vào chất lượng cao, làm gia tăng hiệu năng các mô hình.