RAG vs fine-tuning is often discussed through technical specs. But the real question is simpler: which approach actually solves your problem-and what kind of system are you committing to maintain long term?
Every AI team eventually reaches the same inflection point. The model stops improving. Adding more raw training data yields diminishing returns. Longer training runs flatten out. Benchmarks stall.
That’s when two familiar suggestions surface. One camp proposes fine-tuning. Another argues for Retrieval-Augmented Generation (RAG). Engineers debate efficiency and architecture. Product teams push for speed. Everyone frames the discussion differently while assuming it’s the same decision.
Most online comparisons focus on latency, cost, or infrastructure complexity. This guide looks past those surface metrics to examine when each approach actually makes sense-and which problems you’re solving versus quietly shifting elsewhere.
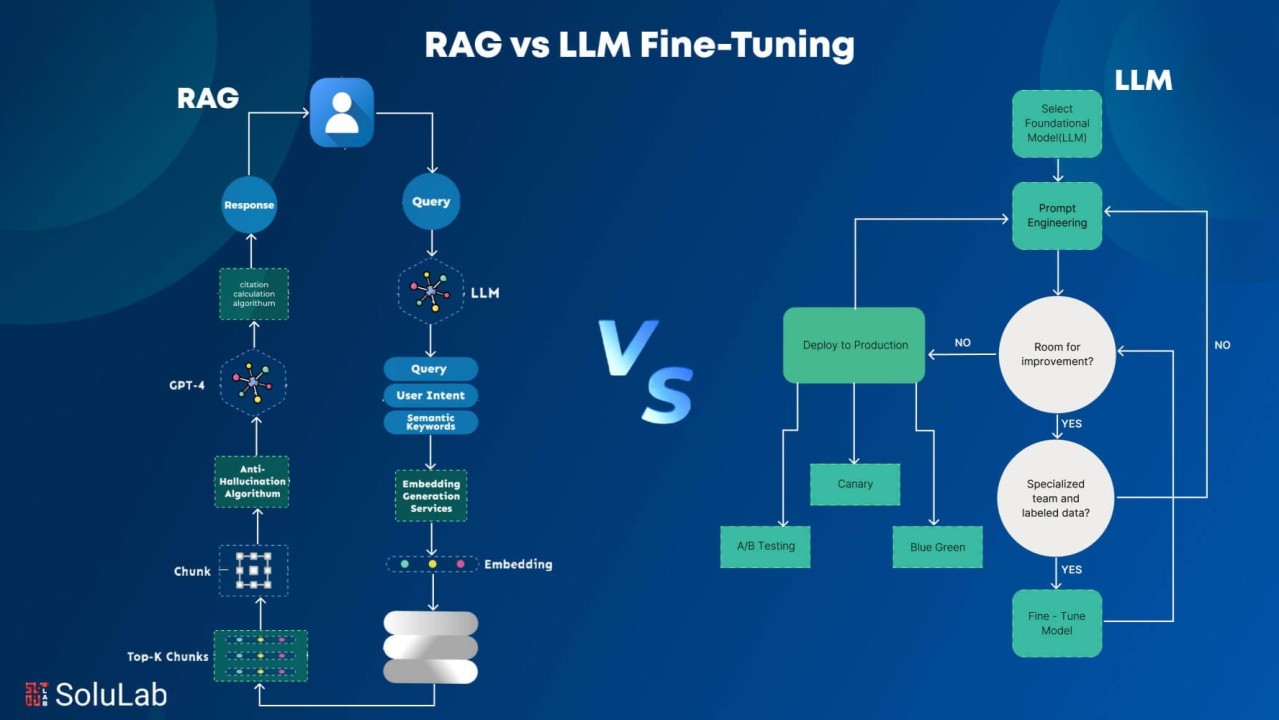
The core differences between RAG vs Fine-Tuning
At a fundamental level, RAG and fine-tuning change different things about how a model behaves.
RAG works by retrieving relevant external information at inference time and injecting it into the model’s context window. The model itself does not learn your domain; it consults better reference material on demand.
Fine-tuning, by contrast, alters the model’s internal weights. It changes how the model processes all inputs by teaching it patterns through examples.
RAG excels when rules, facts, or policies are explicitly written somewhere. If a document states that “Type A contracts require executive approval for amounts exceeding $50K,” RAG can reliably surface that rule and apply it to a $75K contract. But if decision logic is implicit-spread across experience rather than documentation-RAG has nothing to retrieve.
Fine-tuning shines when consistent judgment or pattern recognition is required and cannot be fully articulated in prompts or documents. In these cases, examples outperform instructions.
Each approach also fails differently. RAG can retrieve documents that are topically similar but legally or technically incorrect. Fine-tuning can hard-code flawed labels or biased reasoning into the model itself.
Neither approach eliminates hallucinations. RAG changes what the model hallucinates about. Fine-tuning makes hallucinations more confident when queries fall outside the training distribution.
What RAG actually does
RAG retrieves information at query time and places it in the model’s context window. The model is not learning your terminology or reasoning patterns; it is reading from a better manual.
This distinction matters. Teams often expect RAG to “teach” the model how their organization thinks. It does not. If the logic exists clearly in documents, RAG works well. If it doesn’t, RAG cannot invent it.
The retrieval layer introduces its own risks. Embedding models may treat legally distinct phrases as semantically similar. In one legal system, “material adverse change” was treated as equivalent to “significant negative impact.” The retrieved documents were thematically related but legally wrong, leading the model to generate confident yet incorrect answers.
RAG also does not prevent hallucination. Models routinely cite sections that don’t exist or misattribute sources within retrieved documents. The model is still guessing-it just guesses using different inputs.
What fine-tuning actually does
Fine-tuning modifies the model’s internal behavior by training it on task-specific examples. This changes how it reasons across all inputs, not just those with retrieved context.
This is essential for tasks where logic is embedded in expert judgment. Medical coding is a classic example. The same symptom description can map to different ICD-10 codes depending on patient history, examination findings, and clinical nuance. There is no single document to retrieve that explains this reasoning.
Fine-tuning works because examples demonstrate judgment rather than describing it. Hundreds of annotated cases teach the model which distinctions matter and how experts resolve ambiguity.
Where both approaches fall short
Fine-tuning does not magically make a model “understand” a domain. A model trained on 500 examples will still hallucinate confidently when faced with unfamiliar patterns.
The deeper risk is that fine-tuning internalizes data flaws. If annotations are inconsistent, the model learns that inconsistency as if it were truth.
RAG avoids that particular risk but replaces it with retrieval errors, context dilution, and dependency on embedding quality.
Why teams choose one over the other
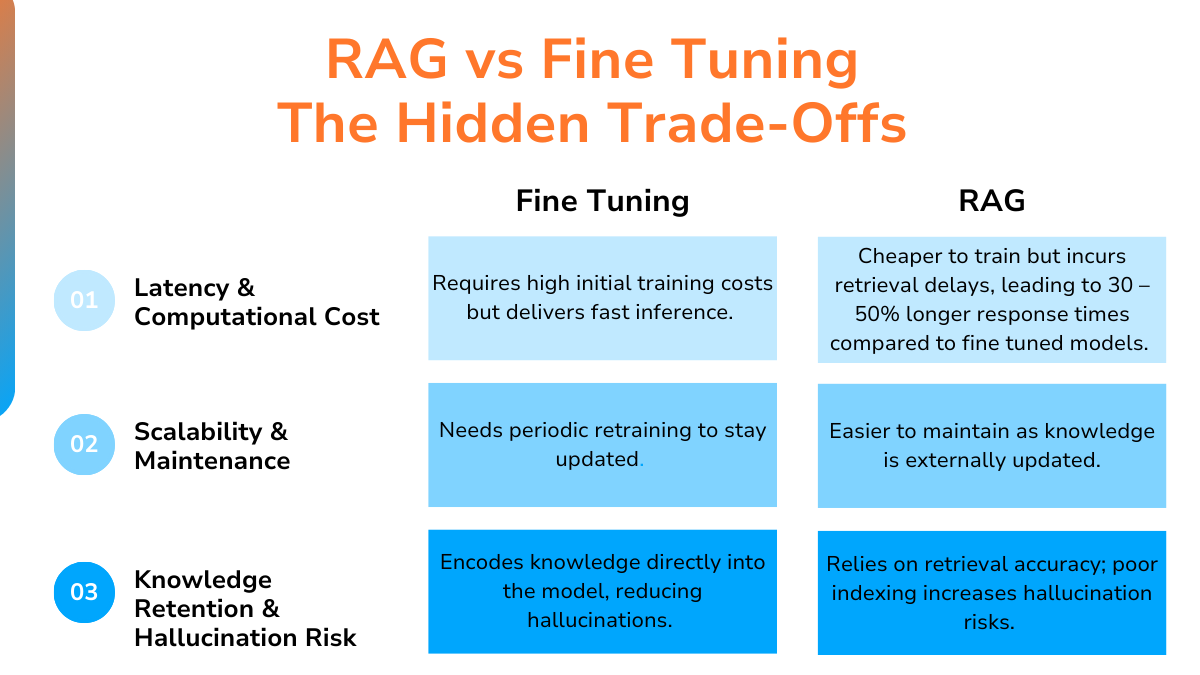
Most teams start with RAG because it is operationally simpler. There is no training pipeline, no model versioning, and knowledge updates do not require retraining.
Teams switch to fine-tuning when RAG hits structural limits: context windows become expensive, retrieval surfaces “almost right” documents, or the task depends on reasoning patterns rather than isolated facts.
One contract analysis team spent weeks optimizing retrieval and stalled at 78% accuracy. Fine-tuning on 300 carefully labeled examples pushed accuracy past 90% in days. The task required recognizing document-wide structure, not pulling individual clauses.
The real decision is not which approach is better in theory. It’s whether your task requires internalized judgment or external reference-and whether your data quality can support either.

When RAG vs Fine-Tuning actually matters
In some scenarios, the choice is decisive. In others, it barely matters.
The knowledge update frequency test
Update velocity is the strongest forcing function. If core knowledge changes frequently, RAG is often the only sustainable option.
A legal compliance team updated its regulatory corpus dozens of times per month. A fine-tuned model became outdated within weeks, requiring constant retraining. Switching to RAG reduced update latency from weeks to minutes.
As a rule of thumb, if critical knowledge changes more than once per quarter, RAG’s flexibility compounds quickly. Fine-tuning carries unavoidable retrain–validate–deploy cycles.
The inverse is also true. When knowledge is stable-such as medical coding standards updated annually-RAG may impose unnecessary inference costs. Fine-tuning can lock in stable logic more efficiently.
Task complexity and the fine-tuning threshold
The second forcing function is behavioral complexity.
RAG handles retrieval and straightforward QA well. Fine-tuning becomes necessary when models must internalize judgment, stylistic consistency, or nuanced decision-making.
One firm needed contract risk assessments aligned with senior partner judgment. RAG retrieved clauses correctly but could not replicate how partners weighed materiality and precedent. Fine-tuning on thousands of partner-reviewed analyses taught the model implicit reasoning patterns that prompts could not convey.
A simple diagnostic: if prompts keep growing longer as you try to “explain” reasoning, you are likely past the point where fine-tuning is more effective.
When your real problem is prompt design
Many RAG vs fine-tuning debates hide a simpler issue: poor prompts.
One support team nearly invested in fine-tuning because RAG responses were inconsistent. The actual problem was vague instructions. After rebuilding the prompt with explicit structure, tone guidance, and edge-case handling, accuracy jumped from 71% to 86-no architectural changes required.
Before investing in fine-tuning, exhaust prompt optimization. Only when clear instructions fail to close the gap does architectural change make sense.
The economic reality
RAG incurs ongoing costs: embeddings, vector storage, retrieval latency. These scale with usage.
Fine-tuning concentrates costs upfront and reduces per-query overhead. At low volumes, RAG is cheaper. At scale, fine-tuning can become more economical.
The correct sequence is simple: eliminate options based on update frequency, evaluate task complexity, optimize prompts, then model long-term economics.
Where both approaches break down
Architecture matters less than most teams believe. Both approaches fail when examples fail.
The example coverage gap
Systems often perform well in testing but fail in production because training examples don’t reflect real-world diversity.
One classifier had 10,000 examples but covered only a fraction of actual user intents. The model learned dozens of ways to cancel a subscription but never saw nuanced requests like pausing billing during extended travel.
Coverage is about representativeness, not volume.
Why synthetic data often backfires
Synthetic data appears attractive when coverage is lacking. In practice, it often worsens performance.
One team generated thousands of synthetic contracts for clause classification. Results looked strong in synthetic tests but collapsed on real contracts, which were messier and more inconsistent than generated data.
Synthetic data helps only when real, high-quality examples already exist and the goal is robustness-not replacement.
Why expert examples beat volume
Performance improves faster with diverse, informative examples than with sheer quantity.
A contract analysis system plateaued until the dataset was rebuilt around edge cases and structural variants rather than redundant standard clauses. Fewer examples, chosen deliberately, produced dramatic gains.
Every example should teach a new distinction. If it doesn’t, it adds little value.
What expert annotation captures
Experts don’t just label accurately; they recognize which cases matter.
In medical coding, value lies in ambiguous, multi-procedure notes-not routine cases. Expert annotators surface boundary conditions that random sampling misses.
Random sampling mirrors data distribution. Expert curation mirrors decision distribution. These are not the same.
Contribute to AI development at Coral Mountain
The choice between RAG and fine-tuning reveals a deeper truth: AI performance is driven by data quality, not architectural elegance.
As these methods standardize, advantage shifts to people who understand what good data looks like-those who can identify edge cases, evaluate context, and design examples that teach models how to reason.
If you bring technical expertise, domain knowledge, or strong analytical thinking, Coral Mountain connects you to real-world AI training work at the frontier of model development.
The path from interest to contribution is straightforward:
- Visit the Coral Mountain application page and apply
- Share your background and availability
- Complete an assessment focused on critical thinking
- Receive an approval decision
- Begin working on projects that directly shape AI systems
Quality matters more than volume. If you understand why that principle drives better AI, Coral Mountain is where that work happens.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves, Vietnamese audio records….