Most teams begin by designing for throughput. They ask how many annotations per hour they can produce, how many workers they can onboard per project, and how fast they can generate examples. Only later do they discover the real constraint: quality.
Completion rates look healthy. Dashboards show steady growth. Yet model performance stalls-or worse, regresses. Months are spent discarding data, rethinking evaluation, and rebuilding systems that should have existed from the start.
We see this pattern repeatedly. Teams come to us after generating millions of synthetic examples, only to realize that a large share must be thrown away. The assumption was that scale would compensate for quality. It never does.
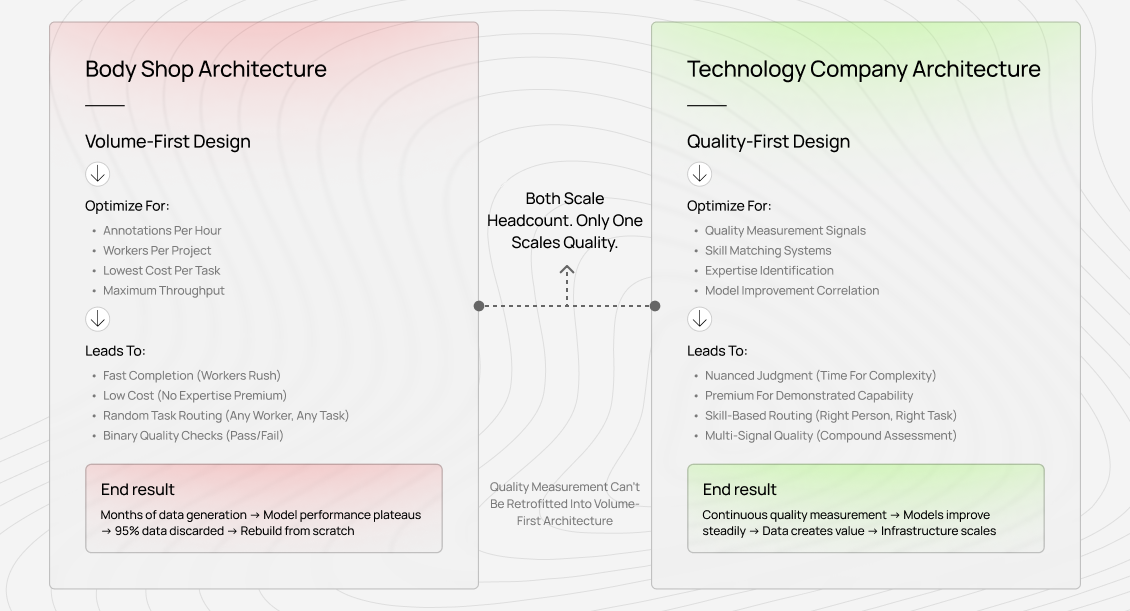
The architectural choice you make at the beginning defines what you are actually building: a labor-scaled body shop, or a technology company with scalable quality infrastructure. Most guides address the first. This one focuses on the second.
1. Start with quality measurement, not data volume
The real bottleneck in AI training infrastructure is not throughput. It is scalable quality measurement. Decisions made in the first few months determine whether your system compounds value-or compounds noise.
Throughput-first design feels natural. Build pipelines that handle millions of examples, hire quickly, generate data fast, and worry about quality later.
This approach fails for one fundamental reason: quality measurement cannot be retrofitted onto volume-first architecture.
Why volume-first architecture breaks
When systems are optimized for throughput, they prioritize speed, low per-task cost, maximum worker utilization, and simple pass/fail checks. Each of these works against quality.
Speed discourages nuanced judgment. Low cost discourages expertise. High utilization ignores skill-task fit. Binary checks only verify instruction compliance, not whether the work teaches the model anything meaningful.
We regularly see companies build massive data pipelines that technically meet specifications-correct format, valid structure, guideline compliance-yet result in models performing worse than baseline. The infrastructure optimized for the wrong objective.
The 99% discard pattern
A common trajectory looks like this: millions of synthetic examples are generated. Production metrics look impressive. Early benchmarks spike. Then real-world evaluations reveal degraded performance. Models overfit to narrow patterns that appear strong but lack true diversity.
After months of analysis, teams keep a small fraction of the data-often under 5%-and discard the rest. Only then do they turn to human-generated data.
The failure was not synthetic data itself. It was an architecture built on the false premise that volume produces quality. In practice, the relationship runs the other way.
Build quality infrastructure first
Quality-first systems ask different questions from the start.
How do we detect not just acceptable work, but exceptional work?
How do we measure quality with enough resolution to distinguish competence from insight?
How do we identify which contributors excel at which kinds of reasoning?
How do these signals survive as we scale from dozens to tens of thousands of contributors?
If these questions are unanswered before pipelines are built, the system is optimizing the wrong constraint.
2. Build your quality signals before your data pipeline
Most AI training platforms treat quality as a filtering step: collect data, then remove bad outputs. This reverses the correct order.
Quality measurement must be the foundation the pipeline is built on, not an add-on.
Define quality at high resolution
The first mistake teams make is reducing quality to binary or coarse ordinal scales. That works for commodity tasks. It fails for work that actually advances frontier models.
High-quality annotations answer deeper questions. Do they teach something the model could not learn from public data? Do they capture reasoning patterns synthetic generation misses? Do they expose edge cases only experts recognize?
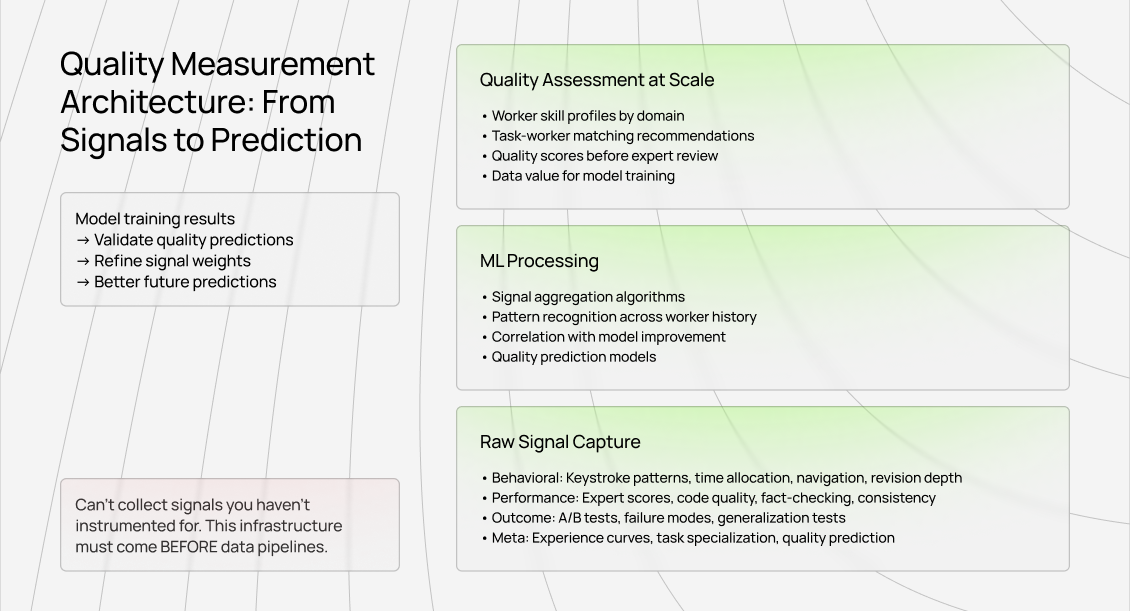
These properties cannot be checked with simple heuristics. They require layered signals that accumulate into a nuanced quality profile.
What real quality measurement looks like
In production systems, quality is inferred from many signals at once. Behavioral traces, such as how work is composed. Performance signals, such as expert reviews across dimensions. Outcome signals, such as which data improves downstream model behavior. Meta signals, such as how quality evolves with experience.
The key principle is automation. High-quality infrastructure captures these signals implicitly, not through manual review alone.
Architecture similar to search ranking
This problem mirrors search ranking. Google cannot manually score web pages. It aggregates thousands of signals and trains systems to predict quality at scale.
The difference is feedback. Search engines rely on user behavior. Training data quality is measured indirectly through model improvement, which introduces longer and noisier loops. But the architectural principle is the same.
Signals first. Models second. Pipelines built on top.
Why this must precede pipelines
Signals that are not instrumented from the beginning cannot be recovered later. If you do not capture how work is produced, you cannot reconstruct that information after the fact. Retrofitting means rebuilding.
This is why quality infrastructure must come first. Once production workloads run, architectural choices become costly to reverse.
3. Design for skill differentiation, not worker fungibility
Commodity annotation assumes interchangeability. Anyone with instructions can do the work. This assumption collapses for modern AI training.
Why standardized instructions do not standardize outcomes
Give two people the same instruction: write an eight-line poem about the moon. Both may comply perfectly. One produces a serviceable poem. The other produces something with layered imagery, internal rhythm, and emotional resonance.
Both pass the task. Only one teaches a frontier model something meaningful.
This gap is not effort. It is accumulated expertise that cannot be transmitted through instructions. The same applies to code review, legal reasoning, medical judgment, and mathematical proof evaluation.
The skill routing problem
If contributors are not interchangeable, infrastructure must route tasks based on demonstrated capability, not availability.
Systems need to learn who handles edge cases reliably, who reasons deeply rather than pattern-matching, whose data correlates with model improvement, and where each contributor excels or struggles.
This is not about hierarchy. It is about aligning expertise with task complexity.
Why credentials are insufficient
Academic or professional credentials are weak predictors of annotation quality. We have seen elite degrees paired with mediocre outputs, and unconventional backgrounds paired with exceptional insight.
Credentials may predict initial performance. Sustained quality must be inferred from observed behavior over time.
Infrastructure should optimize for demonstrated capability, not declared qualification.
4. Treat data pipelines as bi-directional feedback systems
Most pipelines move in one direction: collection to training. This is efficient and blind.
Effective systems propagate signals backward.
The model performance feedback loop
When specific data batches improve certain capabilities, the system should amplify that work. When others correlate with degradation, the system should investigate and adjust.
This requires tagging annotations with rich metadata and correlating training outcomes with data provenance.
The goal is not fault-finding. It is learning which data actually helps models.
Quality measurement as a training signal
Quality infrastructure can also teach contributors. If feedback reveals systematic blind spots, contributors can improve judgment. This transforms annotation from execution into skill development.
The most valuable AI trainers are those whose judgment sharpens over time through feedback, not those who merely follow static rules.
The anti-pattern: optimizing the wrong metrics
Many platforms optimize speed and throughput while ignoring effectiveness. Metrics improve. Model performance does not.
Efficiency without validation only scales failure.
Feedback loops must come first. Optimization should follow once “good” is understood.
- Architect for complexity expansion, not just volume growth
Volume will grow. Complexity will grow faster.
The complexity shift
Early AI training focused on correctness. Today’s training focuses on reasoning quality, edge cases, and judgment. Correctness is often ambiguous. Expertise creates large output variance.
Infrastructure designed for checklists cannot handle this shift.
Infrastructure that adapts
Systems must support new task types without rebuilding core quality mechanisms. New signals, new criteria, and new skill definitions should plug into existing foundations.
Rigid systems lock teams into outdated task models.
The talent pipeline
As complexity increases, scaling requires skill development, not just hiring. Infrastructure should support progression, targeted training, meaningful feedback, and compensation aligned with expertise-not volume.
Platforms that contribute to AGI development treat trainers as professionals whose value compounds over time.
6. Build for quality variance, not quality averages
Commodity systems aim for consistency. Frontier training requires exceptional variance.
Why exceptional work matters
Breakthroughs come from rare examples that demonstrate deep understanding or novel reasoning. Systems optimized for uniform adequacy suppress these examples.
The goal is to eliminate poor work while discovering and amplifying exceptional work.
The discovery challenge
Exceptional outputs are rare. Manual review misses most of them. Infrastructure must surface them automatically through comparative analysis, complexity detection, performance correlation, and expert validation.
The objective is not egalitarian distribution of tasks, but alignment of critical work with the best contributors.
Design systems that teach, not just execute
Execution-only infrastructure produces replaceable workers. Development-oriented infrastructure produces experts.
Systems should show what excellent work looks like, explain why it matters, and connect contributions to model outcomes. Incentives should reward improvement, judgment, and capability growth.
AGI development requires a workforce that becomes more capable over time, not one optimized for static execution.
Contribute to AGI development at Coral Mountain
The teams advancing AGI are not those processing the most data, but those whose infrastructure enables quality measurement, skill differentiation, and continuous improvement at scale.
That is the infrastructure that matters.
If your background includes technical expertise, domain knowledge, or strong critical reasoning, AI training at Coral Mountain places you at the frontier of AI development.
Over 100,000 remote professionals have contributed to this ecosystem.
Getting started involves five steps:
- Visit the Coral Mountain application page and apply
- Complete a brief background form
- Take the Starter Assessment
- Receive your qualification decision
- Select projects aligned with your expertise and begin contributing
No signup fees. Selective standards. One assessment attempt.
Apply to Coral Mountain if you understand why quality beats volume in advancing frontier AI-and you have the expertise to contribute.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves, Vietnamese data…