
Imagine dropping a 500-page PDF into an AI model and asking for a summary. One model processes it effortlessly. Another immediately responds with an error: “This document exceeds the maximum context length.”
Naturally, that feels confusing.
Both models are marketed as cutting-edge. Why does one handle massive documents while the other fails?
The explanation starts with context windows-but the real story goes far beyond the headline token counts used in product comparisons.
A model advertising a 200,000-token context window is not automatically superior to one capped at 32,000 tokens. In practice, it may perform worse. Some models technically accept enormous inputs but quietly lose track of critical information. In other cases, increasing context length introduces confusion rather than clarity.
If you’ve ever seen an AI lose coherence mid-conversation, contradict itself after long exchanges, or produce weaker summaries from longer documents than shorter ones, context windows are the underlying reason. Not merely their size, but how models behave as context expands.
The real issue isn’t how much text a model can ingest. It’s what happens to reasoning, memory, and reliability as that context grows-and why certain lengths introduce failure modes that directly impact how we train and evaluate AI systems.
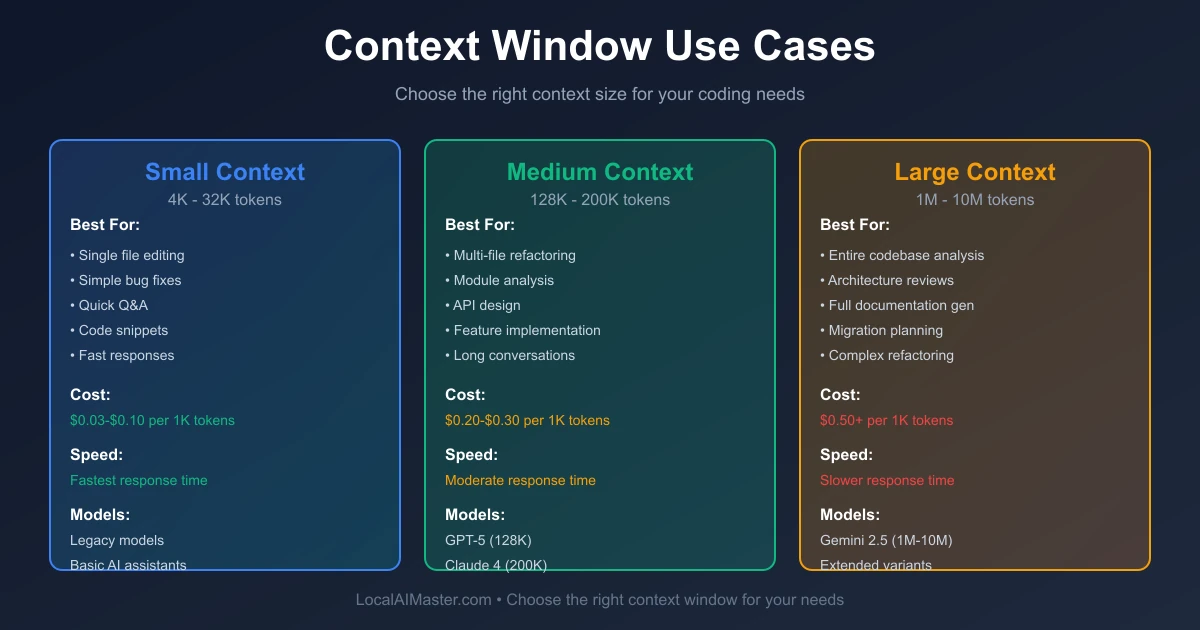
What is a context window?
A context window defines the maximum amount of information a large language model can process and reference at once. This includes both user input and the model’s generated output. You can think of it as the model’s working memory.
Anything outside this window simply does not exist to the model, no matter how relevant it might be.
When you paste a document into systems like ChatGPT or Claude, you are loading that material into the model’s context window. As the model responds, its output also consumes space within that same limit.
Once the combined input and output exceed the allowed context length, something breaks. The model may truncate earlier content, refuse to continue, or begin generating incoherent or unreliable responses.
Tokens as the building blocks of context
Context windows are measured in tokens, not words or characters. In English, a token averages around four characters, but the actual count varies widely. A simple word like “running” may be a single token, while a long technical term may split into several. Code, punctuation, and special characters often consume tokens inefficiently.
This matters because the same token limit accommodates very different amounts of usable content. A 100,000-token window might hold tens of thousands of words of prose, far fewer words of dense technical documentation, or even less if the input is code-heavy.
When designing long-document annotation tasks, we are constantly balancing more than word count. Token density determines whether an evaluation task is feasible at all.
Why context windows determine task complexity
The impact of context windows becomes obvious in real-world evaluation work. Consider a task that asks whether a model can follow instructions consistently across a lengthy technical specification.
With a 4,000-token limit, the document must be split into fragments, breaking continuity and obscuring long-range dependencies. With a 100,000-token window, the entire document can be loaded at once, allowing evaluators to test whether the model remembers requirements introduced early when answering questions far later.
Larger context windows enable fundamentally different categories of tasks. They allow evaluation of cross-document reasoning, long-term consistency, dependency tracking in large codebases, and detection of contradictions spanning tens of thousands of tokens.
This isn’t simply “more text.” It’s a shift in what kinds of reasoning models can even attempt.
Context window sizes of prominent LLMs
Different models support dramatically different context lengths, and these differences define what they can realistically handle.
GPT-4 and GPT-4 Turbo
GPT-4 initially launched with 8,000-token and 32,000-token variants. GPT-4 Turbo expanded that to 128,000 tokens, a leap that fundamentally changed developer workflows.
At smaller limits, models handle conversations, documentation snippets, or single files. At 128,000 tokens, entire research papers, multi-hour transcripts, or large codebases become feasible inputs.
This expansion transformed annotation work from evaluating isolated responses into assessing consistency across complex document hierarchies.
Claude 3 family
Claude 3 introduced context windows of up to 200,000 tokens-roughly equivalent to hundreds of pages of text.
At this scale, entire novels, full API documentation sets, and multi-file software projects can be evaluated in a single interaction. However, longer context also introduces new failure modes. Models that perform well at 50,000 tokens may begin hallucinating or contradicting themselves at 120,000.
Evaluating such behavior requires reviewers who can detect subtle inconsistencies buried deep within massive contexts.
Gemini models
Gemini 1.5 Pro pushed context windows even further, reaching experimental ranges of one million tokens and later stabilizing around two million in production environments.
At this level, entire documentation libraries, historical records, or comprehensive multimedia transcripts can be loaded simultaneously. Tasks often shift from simple response evaluation to synthesis across dozens of independent sources.
The skill required here isn’t just judgment-it’s systems-level reasoning across large information landscapes.
Open source leaders
Open-source models such as Llama 3, Mistral, and Command R+ generally operate within more conservative ranges, often between 8,000 and 128,000 tokens.
Because computational costs increase rapidly with context length, open-source models tend to degrade sooner as contexts grow. This requires more careful task design and tighter scoping to ensure evaluations remain meaningful.
Why do models have a maximum context window length?
Context limits are not arbitrary. They arise from deep architectural constraints that balance feasibility, performance, and cost.
Computational constraints scale quadratically
Transformer models rely on self-attention, where every token attends to every other token. As a result, computational cost grows quadratically with context length. Doubling the window can quadruple the computation required.
At extreme lengths, inference times can balloon from seconds to minutes, making large-scale evaluation impractical.
Memory requirements grow rapidly
Long contexts demand significant memory for attention patterns, intermediate states, and cached values. During training, memory usage can be orders of magnitude higher than during inference.
This creates hard limits imposed by available hardware. In practice, training teams frequently ask whether tasks can be reduced from 150,000 tokens to 100,000-not because the larger context is unnecessary, but because it is physically infeasible to process at scale.
Quality degradation at extreme lengths
Even within supported limits, performance degrades as context grows. A well-known phenomenon, often called “lost in the middle,” causes models to focus disproportionately on recent and early tokens while neglecting information buried deep in the middle.
This means a model may correctly recall details from the beginning and end of a document while completely missing critical information tens of thousands of tokens in.
Effective evaluation must test not only whether information is present in the context window, but whether the model actually uses it.
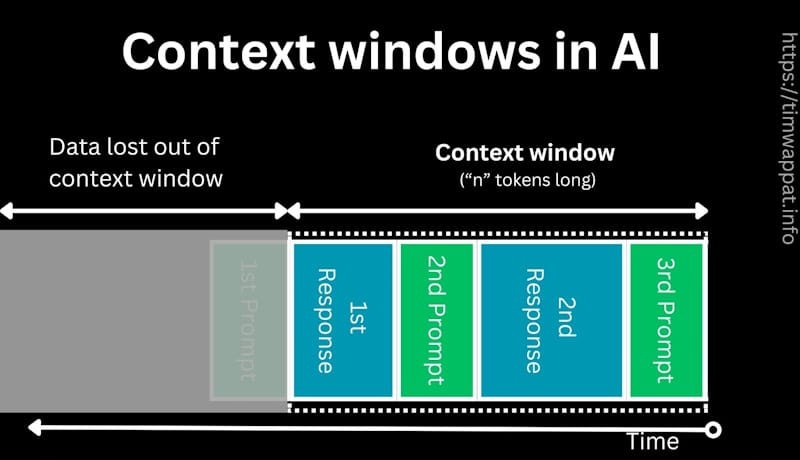
How context window limitations impact AI training work
Context windows shape how training data is designed, evaluated, and scaled.
Task scope expands with context window growth
A few years ago, most annotation tasks fit within a few thousand tokens and involved discrete responses. Today, standard tasks often span 50,000 to 100,000 tokens or more.
Evaluators are asked to assess long-term consistency, cross-file dependencies, and reasoning continuity across massive documents. The work has evolved from isolated judgment to structural analysis.
What this means for task complexity and pay tiers
As context windows grew, so did the cognitive demands placed on evaluators. Reviewing a short code snippet requires local understanding. Reviewing a massive codebase requires architectural insight.
This shift explains why advanced long-context tasks command higher compensation. The effort scales non-linearly, as relationships between elements multiply with context length.
The skills that matter when working with long context
Long-context evaluation rewards capabilities that shorter tasks rarely test:
- Strong working memory to track document structure
- Meticulous attention to detail across wide spans
- Domain expertise to assess technical correctness
- Pattern recognition to identify where models typically fail
Experienced evaluators learn where to look-especially in the middle of long contexts-where errors are most likely to hide.
These skills develop over time and create a widening gap between generalist and expert AI trainers as context windows continue to expand.
Contribute to AGI development at Coral Mountain
The real frontier isn’t how many tokens a model can accept-it’s whether it can maintain reliable, consistent reasoning across that context.
That question defines the future of AI training.
At Coral Mountain, long-context evaluation sits at the center of advancing frontier models. If you bring technical expertise, analytical rigor, and the ability to reason across complex information, this work places you directly at the edge of AGI development.
Thousands of contributors worldwide already support this effort.
If you want to participate, the process is straightforward:
- Visit the Coral Mountain application page and apply
- Submit your background and availability
- Complete the starter assessment
- Receive an approval decision
- Begin working on live projects
No fees. High standards. Real impact.
Apply to Coral Mountain if you understand why quality matters more than volume in training the next generation of AI-and if you have the expertise to prove it.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves, Vietnamese data…