Machine Learning starts with data—but not just any data. The accuracy, fairness, and reliability of your ML models depend directly on how well the data is collected, cleaned, and prepared. In this guide, we’ll explore practical strategies to ensure your data collection workflow delivers high-quality datasets that lead to successful AI outcomes.
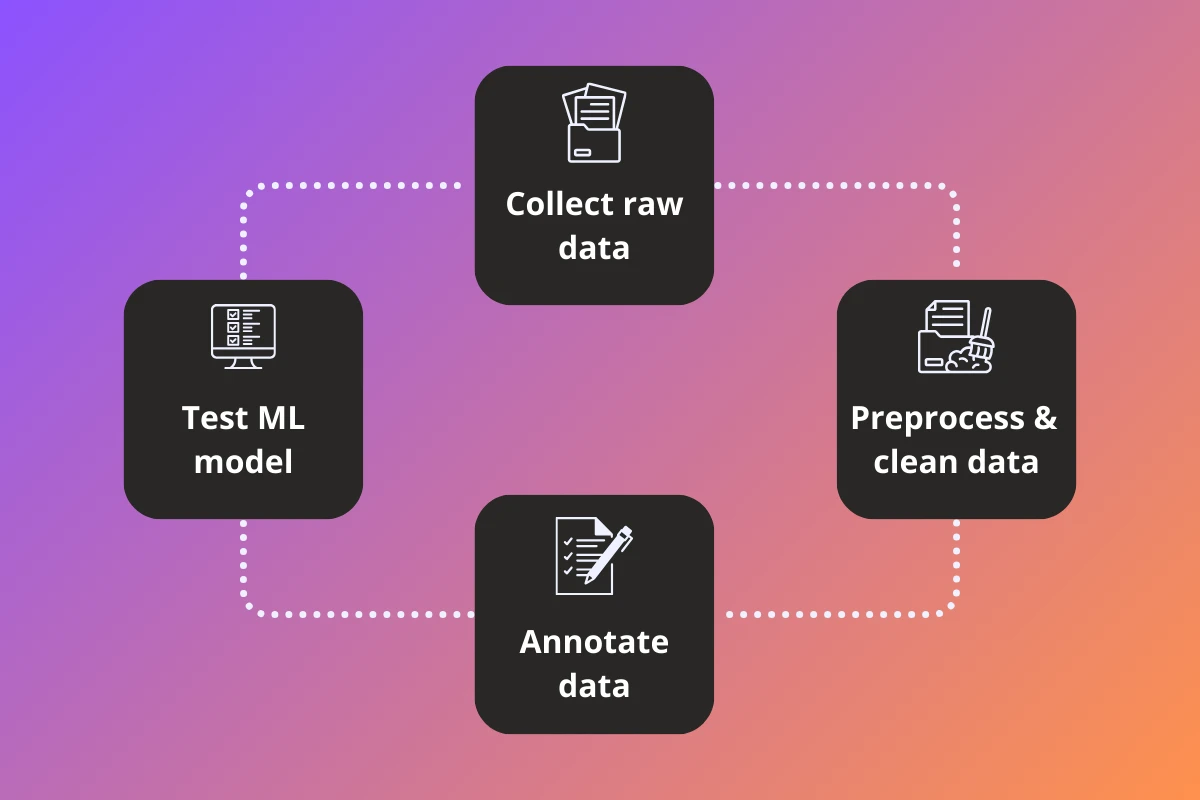
The data collection pipeline
What is data collection and why is it important for ML?
Machine Learning models learn by recognizing patterns. If the data they learn from is biased, inconsistent, or low in diversity, the model will inherit these flaws. This is why data collection must be treated as a strategic phase—not just a supporting activity.
A well-structured data collection strategy can:
- Improve model accuracy and generalization
- Reduce training costs and iteration cycles
- Prevent legal or ethical risks caused by poor data practices
- Create proprietary datasets that serve as long-term competitive advantages
In short: better data beats better models.
Data Collection Process for Machine Learning
The end-to-end data collection pipeline typically includes the following stages:
- Decide the overall strategy
Clarify your use case. Ask:
- What categories or labels do I need?
- How many samples are required for each case?
- Which environments or variations (lighting, weather, demographics, etc.) must be covered?
- Data collection
Depending on the project, this might include web scraping, surveying users, recording sensor data (e.g., cameras, LiDARs), or manual field collection.
- Data preprocessing
Raw data nearly always contains noise. This step removes unreadable samples, blurry images, exposure errors, corrupt files, or irrelevant items.
- Data annotation
Once cleaned, the data must be tagged with meaningful labels—objects, classes, attributes, metadata, or free-form notes. Annotation quality directly impacts model performance.
- Data augmentation
If the dataset is small or lacks variation, synthetic variations are introduced via flipping, blurring, cropping, or color shifting. This improves robustness without collecting more real-world samples.
Data Sources
Your data can come from internal or external sources—or a hybrid mix.
Internal data sources
This includes data already generated inside your business (e.g., CRM logs, security camera footage), or new data collected intentionally for ML. For example, sending a team to capture images of supermarket shelves if you’re building a retail recognition model.
Advantages include:
- Full ownership and control
- Alignment with real-world deployment conditions
The trade-off: internal collection is more resource-intensive.
External data sources
These include public datasets (Kaggle, OpenImages), APIs (Twitter, Flickr), or commercial dataset providers. They are ideal for prototyping or benchmarking, but may not align perfectly with your real deployment environment.
Always verify licensing, usage rights, and ethical sourcing.
Dataset Licenses

Popular sources for finding publicly available datasets
Before using external data, confirm its terms of usage. Some licenses allow commercial use, while others restrict data to research only or require attribution.
- Public Domain / CC0 – Freely usable without restrictions.
- CC BY / ODC-BY – Free to use with attribution.
- CC BY-NC (Non-Commercial) – Not allowed for business or monetized projects without permission.
When in doubt, consult your legal team or request clarification from the data provider.
Data Quality

Data annotation is a key step in preparint datasets for Machine Learning
Even a large dataset is useless if it’s inconsistent or biased. High data quality requires attention in three areas:
Missing Data Handling
Instead of ignoring missing values, use structured strategies such as:
- Imputation (mean/median/mode replacement)
- Model-based filling (e.g., regression or k-NN interpolation)
- Selective removal if the impact is minimal
Data Cleaning
- Remove duplicates, especially in video frames or continuous sensor data
- Detect outliers, which can represent either critical edge-cases or corrupted samples
Creating high-quality annotations
Poor labeling is just as harmful as poor collection. Annotation must be:
- Consistent (same rules applied across annotators)
- Context-aware (understanding domain-specific differences)
- Validated with regular QA checks
Tools and platforms like Coral Mountain’s annotation suite support multi-layer labeling, real-time previews, and assisted segmentation features to ensure consistency across large teams.
Synthetic Data Generation
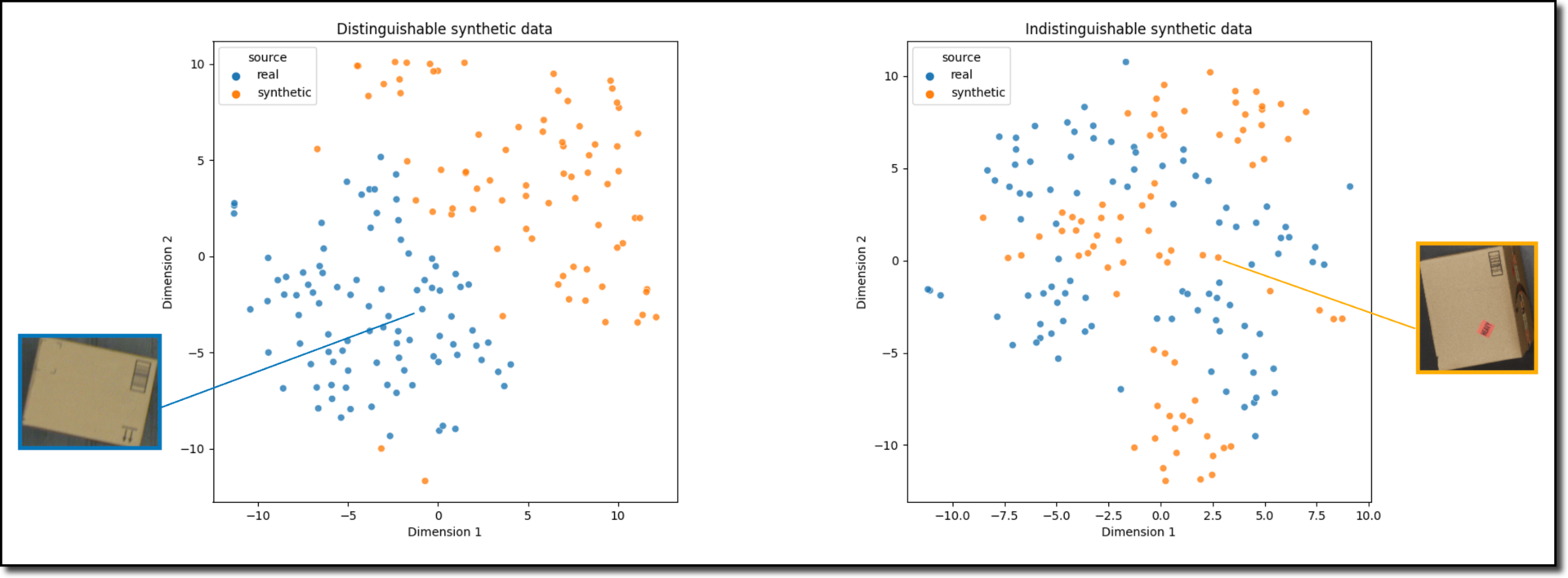
Sythetic data generation attempts to model the true data distribution of the real data and then samples a new data point from the distribution
When real-world data is difficult to collect, synthetic data can accelerate development.
- Generative Adversarial Networks (GANs) can mimic real distributions—for example, generating rare defect samples in manufacturing.
- Programmatic data augmentation enhances diversity without collecting more raw samples.
Synthetic data is especially useful for rare events, safety-critical edge cases, or privacy-restricted domains like healthcare.
Challenges in Data Collection for ML
Data Privacy and Ethics
- Handle PII (Personally Identifiable Information) with care.
- Use anonymization and secure storage.
- When outsourcing annotation, verify worker conditions and data handling policies.
Data Bias and Fairness
A dataset that overlooks minorities or environment variations will produce biased models. Always examine:
- Demographics
- Lighting / geography / cultural variation
- Class balance
Bias correction often requires targeted collection rather than random gathering.
Continuous Iteration and Improvement
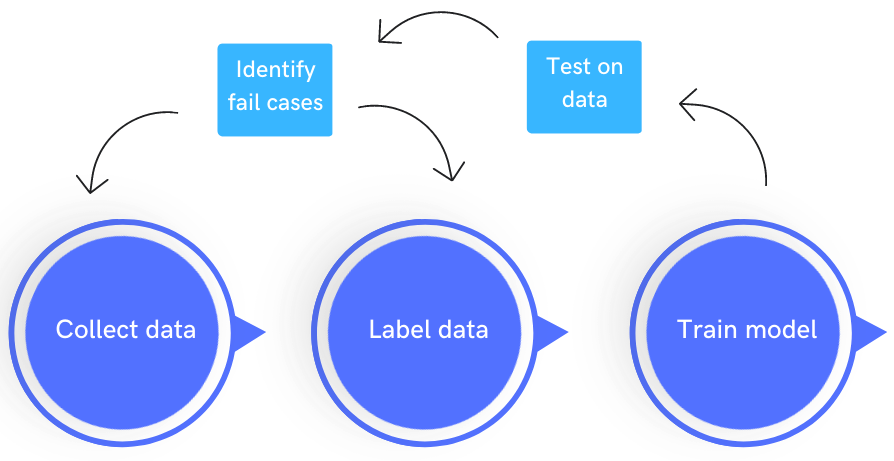
The Data centric approach to improving ML models
Data collection is not a one-off project. Modern AI companies operate in data loops, where real-world feedback is continuously fed back into the dataset for improvement.
This approach—known as Data-Centric AI—prioritizes refining your dataset before tweaking your architecture. In many cases, better data yields more improvement than moving from one model architecture to another.
A Machine Learning model is only as strong as the data behind it. By investing in a structured data collection strategy—one that balances internal and external sources, prioritizes quality and ethics, and encourages continuous improvement—you enable AI systems that are accurate, fair, and scalable.
Great models aren’t discovered—they’re built. And they start with great data.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….