Every regulated AI deployment demands explanations. Yet most deployed explanations merely satisfy compliance requirements without offering any real insight into how models behave.
LIME explanations fluctuate with minor parameter changes. SHAP computations can take hours on production-scale systems. Attention weights are often mistaken for causal importance. Gradient-based techniques tend to amplify noise in deep networks.
Each widely used explainable AI (XAI) method comes with well-documented limitations. Still, teams deploy them as if they provide ground truth about model reasoning — then act surprised when real-world performance diverges from what those explanations seemed to promise.
The problem isn’t that these methods are broken. They generally work exactly as designed. The real gap is one of expectation: what practitioners need from explainability versus what today’s tools are actually built to deliver.
This article explores which XAI methods genuinely help teams understand and improve model behavior, which ones function primarily as compliance theater, and how to assess whether your interpretability stack offers real insight or just polished optics.
What “works in practice” means for explainable AI methods
Before judging individual techniques, we need to define what “working” actually means in real-world settings.
Much of the XAI literature prioritizes fidelity — how accurately an explanation reflects internal model behavior. Fidelity matters, but it’s not enough. An explanation can be technically faithful and still completely useless.
In operational environments, utility matters more than theoretical elegance.
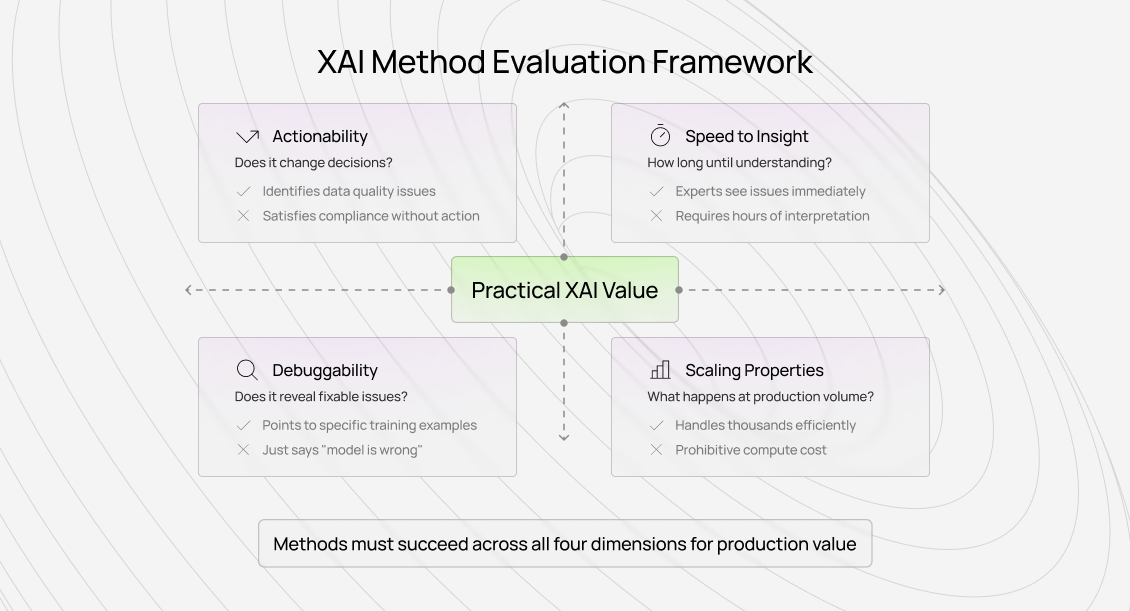
Actionability: Does it change decisions?
The most basic test: does the explanation lead to different decisions than you would have made without it?
Real actionability looks like:
- Discovering and correcting data quality issues through explanation patterns
- Choosing between model architectures based on what features they actually learn
- Debugging production failures by tracing which inputs drove incorrect predictions
- Identifying bias or fairness issues via systematic feature attribution
Non-actionability looks like:
- Generating explanations that stakeholders review but never act on
- Producing visualizations meant to “build trust” without enabling improvement
- Checking regulatory boxes that no one meaningfully audits
- Documenting behavior without informing future decisions
In practice, we track this explicitly. If an interpretability tool rarely leads to concrete actions — guideline updates, data corrections, architectural changes — it’s theater, regardless of how sophisticated it appears.
Speed to insight: How quickly does understanding emerge?
Useful explanations surface insight fast. If experts spend hours parsing explanations without reaching clear conclusions, the method fails operationally even if it succeeds academically.
The strongest XAI implementations allow domain experts to immediately judge whether model behavior makes sense:
- Doctors can quickly assess whether reasoning aligns with medical knowledge
- Annotators can tell whether quality models learned real indicators or artifacts
Insight that arrives slowly is expensive. If interpretation requires deep ML expertise, it won’t scale beyond a small technical team.
Debuggability: Does it expose fixable problems?
High-value explainability pinpoints why something went wrong in a way that enables correction:
- Identifying spurious correlations the model relied on
- Revealing annotation shifts that degraded performance
- Highlighting training examples that caused specific failures
Methods that only describe behavior without suggesting how to improve it answer “what” but not “why,” limiting their practical value.
Scaling properties: What happens in production?
Academic demos often explain dozens of predictions. Production systems require explanations at massive scale.
Some methods collapse under compute cost. Others remain individually reasonable but produce contradictions when aggregated across thousands of cases. Any serious evaluation must consider:
- Can explanations be generated at production volume?
- Can humans review them efficiently at scale?
- Does explanation quality degrade as volume grows?
The operational reality of explainable AI methods
Let’s evaluate major XAI approaches through a production lens.
LIME: elegant concept, unstable execution
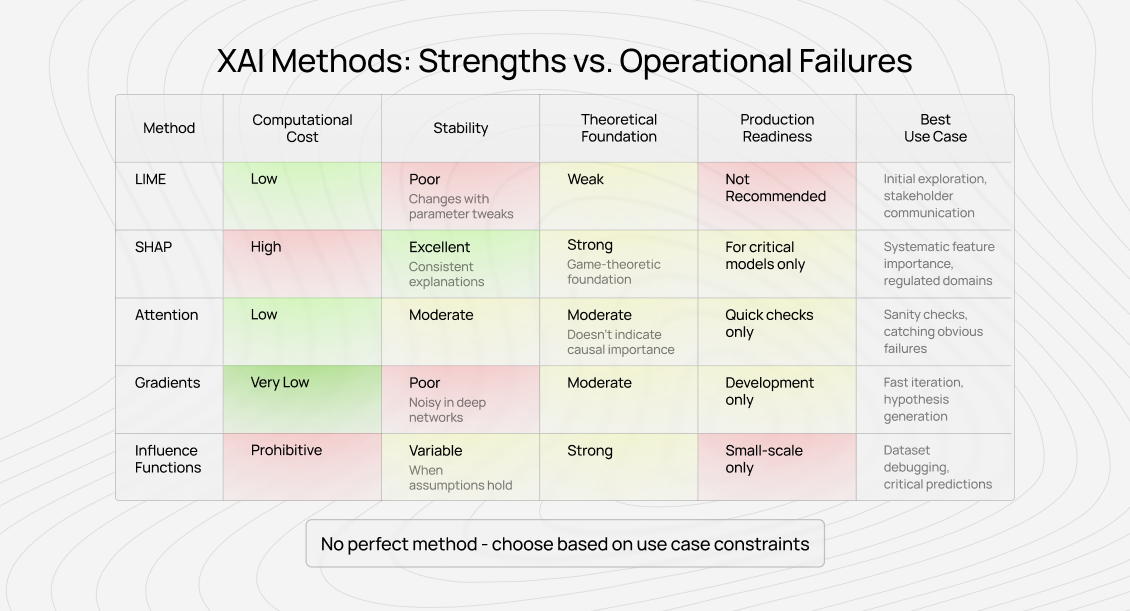
LIME (Local Interpretable Model-Agnostic Explanations) is popular because it’s intuitive and model-agnostic.
Where it helps:
Rapid prototyping and early-stage exploration. LIME provides quick intuition about potentially relevant features and produces visuals that non-technical stakeholders can understand.
Where it breaks down:
Stability. Small parameter changes can produce dramatically different explanations for the same prediction. This isn’t a bug — it’s intrinsic to LIME’s design — but it undermines trust.
More fundamentally, LIME doesn’t explain what the model actually did. It explains what a simple surrogate model would do if it approximated the complex model locally. That extra layer of approximation often produces explanations that feel plausible while misrepresenting reality.
Practical guidance:
Use LIME for exploration and communication only. Never rely on it for systematic debugging or monitoring. Always validate insights with other methods.
SHAP: principled, but expensive
SHAP grounds explanations in game theory, addressing LIME’s instability with mathematically consistent attributions.
Where it helps:
Aggregated feature importance analysis. SHAP explanations can be meaningfully compared across predictions, making them valuable for systematic quality evaluation — especially for tabular data.
In annotation quality systems, consistent SHAP patterns often justify updates to evaluation rubrics because the attribution is reliable.
Where it struggles:
Compute cost. Exact SHAP scales poorly for large or high-dimensional models. Approximations reduce cost but reintroduce instability.
SHAP also assumes feature independence — an assumption that rarely holds in real-world data, potentially distorting attributions for correlated features.
Practical guidance:
Worth the cost for regulated or high-stakes systems. Use TreeSHAP where applicable. For rapid iteration, the overhead may not be justified.
Attention visualization: intuitive but misleading
Transformers made attention maps popular, seemingly offering a window into model reasoning.
Where it helps:
Sanity checks and structural debugging. Attention patterns can reveal when models focus on formatting artifacts, position markers, or annotation quirks instead of meaningful content.
This has repeatedly exposed guideline issues that accuracy metrics alone would miss.
Where it fails:
Attention does not equal causation. Tokens with high attention weight aren’t necessarily important to the final prediction. Models can perform similarly even with randomized attention.
The biggest risk is overinterpretation. Heatmaps feel authoritative, tempting stakeholders to assume highlighted tokens “caused” the decision.
Practical guidance:
Use attention for quick diagnostics, not as proof of reasoning. Validate findings through ablation before acting.
Gradient-based methods: fast, but noisy
Saliency maps and Integrated Gradients offer cheap, general-purpose explanations.
Where they help:
Rapid debugging, especially in vision models. They provide immediate feedback about influential regions or tokens.
Where they fail:
Noise, saturation, and baseline sensitivity. Deep networks often produce gradients that don’t align with human-interpretable importance.
Practical guidance:
Excellent for hypothesis generation during development. Insufficient for high-stakes or compliance use without further validation.
Influence functions: powerful in theory, fragile in practice
Influence functions trace predictions back to specific training examples.
Where they shine:
When they work, they’re unmatched — pinpointing mislabeled data or problematic samples enables direct fixes.
Where they struggle:
Compute cost, numerical instability, and broken assumptions in real neural networks. Approximations help but reduce reliability.
Practical guidance:
Best suited for small models or targeted investigations. Rarely practical at full production scale.
How to evaluate explainable AI (XAI) methods for your use case
There’s no universally “best” XAI technique. The right choice depends on your operational goals.
Start from requirements, not tools
Most teams adopt popular methods first, then search for use cases. This almost guarantees disappointment.
Instead, ask:
- Are you debugging failures?
- Meeting regulatory obligations?
- Communicating with non-technical stakeholders?
- Detecting data quality issues?
- Verifying models learned real patterns, not shortcuts?
Different goals demand different methods.
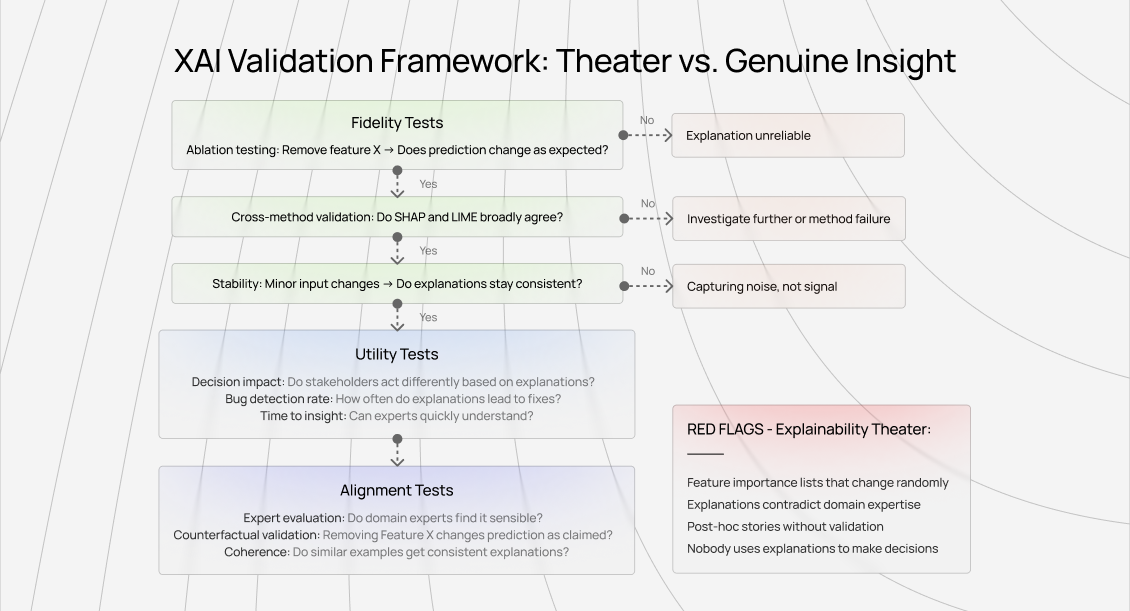
Validate explanations, don’t trust them
Every explanation should face scrutiny:
- Ablation testing: Remove claimed-important features and verify impact.
- Cross-method checks: Multiple methods should broadly agree.
- Expert review: Domain experts should find explanations plausible.
Optimize for utility, not elegance
Track:
- Whether explanations change decisions
- Time to actionable insight
- Consistency across similar cases
If explanations don’t influence outcomes, they fail — regardless of fidelity.
Applying explainable AI methods in AI training work
Explainability reshapes how quality, expertise, and accountability work in AI training.
Quality patterns become explicit
Explainable quality systems reveal what actually differentiates strong work from weak work. This transforms feedback from subjective judgment into concrete, actionable guidance.
Domain expertise gains leverage
Not all expertise matters equally. XAI reveals which kinds of knowledge actually improve model outcomes, helping experts focus effort where it counts.
Standards become measurable
Vague criteria like “accuracy” become specific once explanations expose the patterns models learned. Quality evolves from opinion to skill development.
Contribute to AGI development at Coral Mountain
The explainable AI systems shaping frontier models depend on human intelligence that synthetic data can’t replace.
When explanations expose what truly matters, when quality feedback becomes precise and actionable, that loop relies on people who understand both the domain and the implications.
If your background includes technical expertise, domain knowledge, or the ability to evaluate complex trade-offs, AI training at Coral Mountain places you close to the real work of advancing general intelligence.
Tens of thousands of remote contributors support this infrastructure.
If you want to participate, the path is straightforward:
- Visit the Coral Mountain application page
- Share your background and availability
- Complete the assessment focused on reasoning and judgment
- Review the decision once notified
- Begin contributing to live projects
No fees. High standards. Quality over volume.
If you understand why explainability must deliver insight — not just optics — and you have the expertise to contribute, Coral Mountain is where that work happens.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves, Vietnamese data…