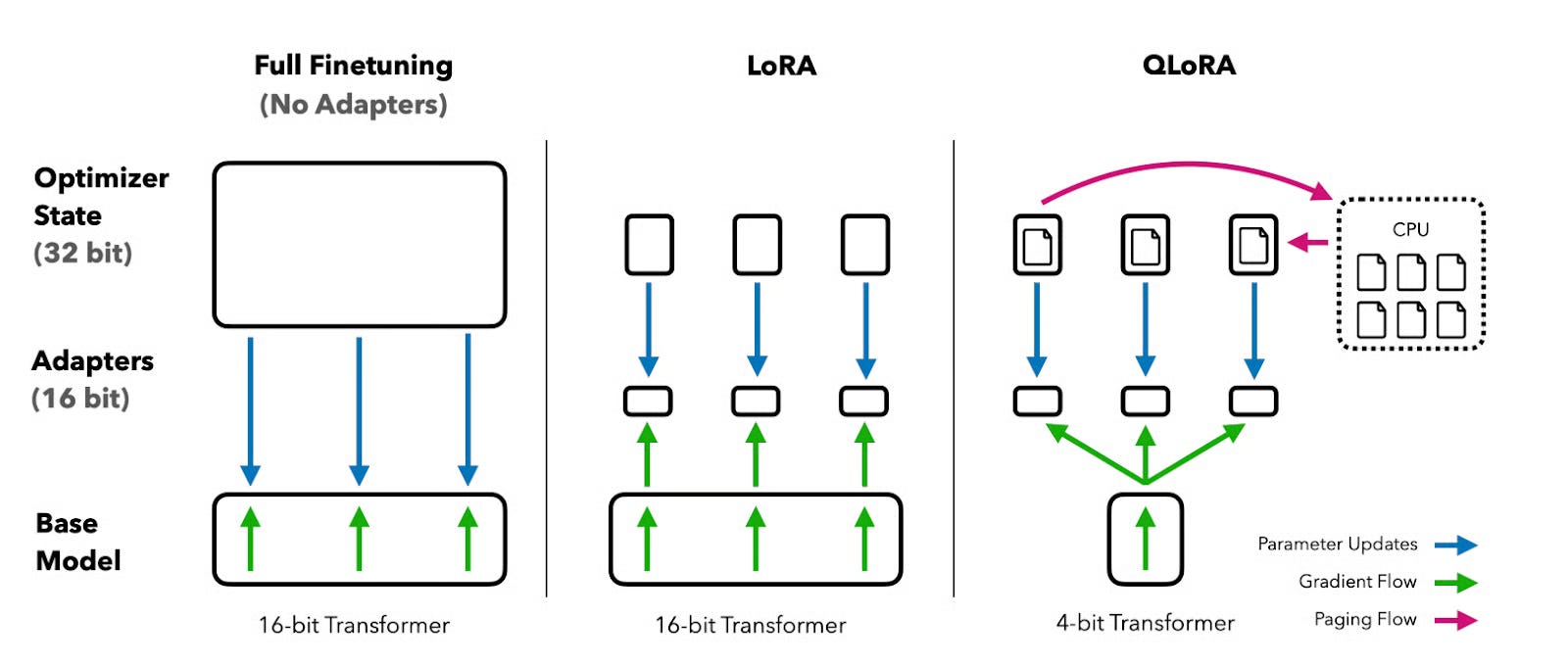
You’ve probably heard the pitch around Low-Rank Adaptation (LoRA): it dramatically reduces fine-tuning costs. Train only a tiny fraction of parameters-sometimes as little as 0.01%. Cut GPU memory usage by multiple times. Achieve 90% of the quality of full fine-tuning. Maybe even 95%.
All of that is true. LoRA does exactly what it claims to do.
What’s usually left out is the second-order effect: when fine-tuning becomes cheap, teams run far more experiments-often on worse data. Efficiency increases. Quality problems scale faster.
In production, the pattern repeats. The model performs flawlessly on straightforward inputs, yet struggles with ambiguity, conflicting instructions, or cases that demand nuanced understanding beyond what a compressed parameter space can capture.
LoRA works. But optimizing for efficiency instead of capacity often widens the gap between “passes validation” and “holds up in production.”
Understanding when LoRA genuinely improves fine-tuning-and when it merely masks data issues-matters more than understanding the math behind it.
What is Low-Rank Adaptation (LoRA)?
LoRA is a parameter-efficient fine-tuning method that trains small adapter matrices while keeping the base model frozen. Instead of updating billions of parameters, LoRA learns a low-rank representation of the task-specific update.
The core idea is simple: most fine-tuning updates live in a low-dimensional subspace.
Rather than modifying a full weight matrix directly, LoRA expresses the update as the product of two much smaller matrices. If a layer contains a large square matrix, LoRA replaces its update with a compact decomposition that captures only the most salient changes.
The base model remains untouched. Only the adapters learn. At inference time, those adapters can be merged back into the model or swapped dynamically depending on the task.
Key features of LoRA
Several design choices explain both LoRA’s strengths and its limitations.
The rank parameter determines capacity. A higher rank allows the adapter to represent more complex changes but reduces efficiency. There’s no reliable way to know the “right” rank ahead of time; it depends entirely on task complexity.
LoRA is often applied selectively, typically to attention layers rather than the entire network. This assumes that task-specific behavior concentrates in attention mechanisms, an assumption that holds for many tasks-but not all.
A scaling factor controls how strongly the adapter influences the base model. Higher values increase adaptation but raise the risk of overwriting useful general capabilities. Common defaults exist, but they’re conventions, not theory.
Everything except the adapters remains frozen. This preserves pre-trained knowledge, assuming the task is a variation of something the model already understands rather than a fundamentally new domain.
Finally, LoRA adapters can be merged or kept separate. Merging simplifies deployment. Keeping them separate allows flexible multi-task serving. Most production teams choose simplicity unless they truly need dynamic swapping.

LoRA vs. other AI fine-tuning techniques
LoRA is one approach in a broader ecosystem of parameter-efficient fine-tuning methods. Each method reflects a different assumption about where task-specific knowledge lives.
Some techniques embed knowledge into prompt-like tokens. Others insert bottleneck layers. LoRA assumes task adaptation can be expressed as a low-rank weight update.
All of these approaches reduce cost. None guarantees quality across all tasks.
LoRA tends to perform well on narrow or well-defined tasks such as classification or simple instruction following. It struggles more on complex reasoning problems where the required adaptation doesn’t fit neatly into a low-dimensional space.
In practice, it’s common to see LoRA and full fine-tuning achieve identical validation metrics-yet behave very differently on edge cases. The metrics rarely capture what actually matters.
How does LoRA work?
Conceptually, LoRA replaces a full parameter update with a structured approximation.
Instead of learning a complete update to a weight matrix, the model learns two smaller matrices whose product represents the change. During training, gradients flow only through these adapters. The base weights never move.
The rank controls how expressive this approximation can be. Low ranks work surprisingly well for simple adaptations. Higher ranks approach the capacity of full fine-tuning but erode the efficiency benefits that motivated LoRA in the first place.
Most implementations focus on attention layers, especially query and value projections. This choice is empirical rather than theoretical, and task-dependent. Some applications benefit from broader coverage, others do not.
Initialization and scaling choices determine how aggressively the adapter alters behavior. Teams sometimes increase scaling to chase quality, only to discover that the model has lost basic capabilities it previously handled well.
After training, adapters can be merged into the model or retained separately. Merging eliminates inference overhead but removes flexibility. Keeping adapters separate supports multi-task systems at the cost of slight complexity.
What are the applications of LoRA in AI development?
LoRA excels when the base model already understands the domain and the goal is behavioral adaptation rather than conceptual learning.
It works well for domain-specific chatbots where tone, terminology, or formatting needs adjustment. The model already knows how to converse; LoRA nudges it toward a specific style or knowledge boundary.
Style and tone adaptation is another strong fit. LoRA can capture consistent stylistic patterns efficiently-provided the training examples clearly demonstrate those patterns. If the examples vary widely in quality, the adapter learns the average, not the ideal.
Task-specific instruction following also benefits. If the model already understands the task class, LoRA can enforce structure, conventions, or policy constraints without retraining the entire network.
Finally, LoRA enables multi-task serving through adapter swapping. A single base model can support multiple behaviors by loading different adapters. The tradeoff is minimal latency and the need for routing logic.
What the papers don’t tell you about LoRA AI training
Research papers emphasize validation metrics. Production exposes what those metrics miss.
Teams often discover that LoRA models fail silently when rank selection is insufficient. Training loss improves. Validation looks fine. Deployed behavior degrades on nuanced cases.
There’s no principled way to choose rank. Teams experiment until performance seems acceptable, often without realizing what kinds of failures remain untested.
LoRA also amplifies data quality issues. Its efficiency encourages rapid iteration, which shifts attention toward hyperparameters rather than training data. Bad data gets processed faster, not fixed.
While LoRA reduces catastrophic forgetting compared to full fine-tuning, it doesn’t eliminate it. Errors present in the training data can become concentrated in the adapter’s subspace and dominate behavior in certain contexts.
When problems arise, the solution is rarely a different LoRA configuration. It’s almost always better data.
Why LoRA efficiency doesn’t guarantee AI quality
Before parameter-efficient fine-tuning, training was expensive, so teams were careful. Now it’s cheap, and experimentation becomes casual.
Iteration speed creates the illusion of progress. Teams run dozens of experiments, tweaking rank and scaling, while the training data remains fundamentally flawed.
Meanwhile, evaluation lags behind training speed. Models can be trained in hours, but rigorous human evaluation takes much longer. Automated metrics fill the gap, even though they fail to capture real-world performance.
Method choice becomes a distraction. It feels concrete and testable. Data quality feels subjective and endless. Yet data quality overwhelmingly determines final model behavior.
The data quality factor in LoRA fine-tuning
Across fine-tuning projects, one pattern repeats: model quality correlates weakly with method choice and strongly with data quality.
High-quality fine-tuning data clearly demonstrates desired behavior, includes meaningful edge cases, maintains consistency, and avoids contradictions.
A small, carefully curated dataset often outperforms a much larger mediocre one. Efficiency doesn’t change this relationship.
Annotator expertise shows up most clearly in ambiguous cases. Expert-curated data teaches models how to reason under uncertainty, not just how to answer obvious questions.
General annotators can follow instructions. Specialists understand what good performance actually looks like. That difference rarely appears in validation metrics-but it appears immediately in production.
What LoRA advancement means for AI trainers
As fine-tuning becomes easier, the value of expertise increases.
Basic data formatting becomes commoditized. Domain knowledge, judgment, and the ability to identify subtle failure modes become differentiators.
The work shifts from generating large volumes of data to curating small sets of high-impact examples. This favors specialists over generalists.
Career paths diverge. Routine annotation compresses toward automation. Domain-specific curation, evaluation, and strategy grow in value.
Efficient methods like LoRA don’t reduce the need for human expertise. They increase competition-and raise the premium on quality.
Contribute to AGI development at Coral Mountain
Every efficiency breakthrough in AI training follows the same pattern: iteration accelerates, but quality remains constrained by training data and human judgment.
At Coral Mountain, contributors with technical expertise, domain knowledge, and strong evaluative skills play a central role in advancing frontier AI systems.
Thousands of remote contributors already support this work.
To get started:
- Visit the Coral Mountain application page
- Submit your background and availability
- Complete the starter assessment
- Receive an approval decision
- Begin working on active projects
No fees. High standards. Real impact.
Apply to Coral Mountain if you understand why quality beats volume in advancing AI-and if you have the expertise to make that difference.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves, Vietnamese data…