What is explainable AI (XAI)?
Explainable AI (XAI) refers to techniques that make model decisions understandable to humans.
The core challenge is structural: modern AI systems-especially deep neural networks-learn representations across massive parameter spaces that humans cannot directly interpret.
A medical imaging model might detect cancer with exceptional accuracy. When asked why, the truthful explanation involves activation patterns across tens of millions of weights-information no clinician can act on.
XAI attempts to translate this internal behavior into human-meaningful terms:
- Which features influenced the decision?
- Which examples mattered most?
- What changes would alter the outcome?
The field includes:
- Interpretable-by-design models (e.g., linear models, decision trees)
- Post-hoc explanation techniques applied to black-box systems
The distinction that matters most in practice:
Explaining what a model did is not the same as explaining why it worked.
Most XAI methods achieve the former. Very few achieve the latter.
What are the differences between AI and XAI?
Traditional AI development optimizes almost exclusively for predictive performance. If accuracy improves, internal reasoning is rarely questioned.
XAI introduces a second objective: human interpretability, which often conflicts with raw performance.
A highly accurate ensemble may offer feature importance scores, yet remain opaque in practice.
A deep neural network may outperform simpler models while offering no native explanation at all.
Teams encounter real-world friction here. I’ve seen:
- High-performing models rejected because stakeholders couldn’t interrogate decisions
- Accuracy sacrificed for interpretability, only to discover explanations were still unusable
The real problem isn’t choosing AI or XAI.
It’s understanding:
- When explainability is genuinely necessary
- When accuracy trade-offs are justified
- When explanation requirements exist mainly to satisfy formal checklists
Why explainable AI matters
Explainability is often framed around regulation and trust. Those matter-but they’re not the whole story.
Regulatory and legal constraints
Healthcare, finance, and credit decisions operate under legal obligations to justify automated outcomes. Without explanations, deployment may be impossible regardless of performance.
Debugging and model improvement
This is where XAI delivers its most immediate value. Knowing why a model fails exposes systemic issues-data leakage, spurious correlations, or annotation drift-that metrics alone conceal.
Stakeholder adoption
Domain experts are rightly skeptical of systems they cannot interrogate. Resistance often reflects an understanding that models can be correct for the wrong reasons.
Bias and fairness detection
Without insight into decision drivers, it’s impossible to distinguish genuine predictors from proxies for protected attributes. Fairness audits require interpretability.
Data pipeline visibility
At Coral Mountain, we view explainability as equally relevant to data pipelines as to models.
Shifts in annotation quality or guideline interpretation can change what models learn without noticeably affecting headline metrics. Explainability tools surface these changes.
When feature importance patterns shift or attention distributions change across checkpoints, it signals upstream issues-annotator drift, ambiguous guidelines, or evolving data distributions.
Interpretability turns models into diagnostics for their own training data.

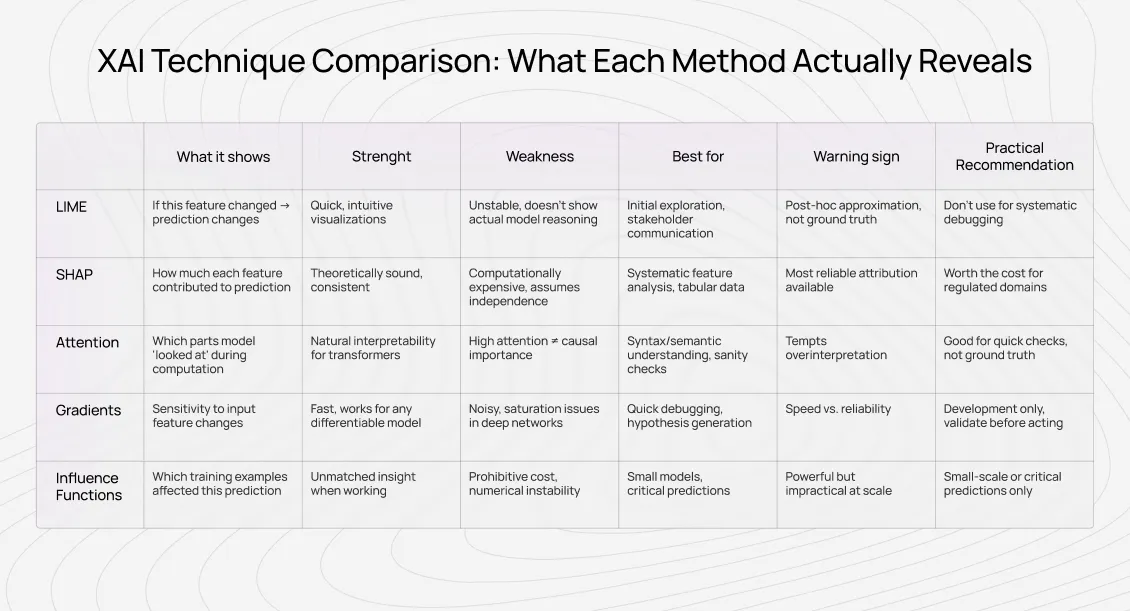
5 core explainable AI techniques and how they work
Below are the most common XAI approaches-and what they truly reveal.
- Local Interpretable Model-Agnostic Explanations (LIME)
LIME approximates a complex model locally with a simpler one by perturbing inputs and observing output changes.
What it shows:
Which features, if altered, would most affect this specific prediction.
Strengths:
Useful for local sensitivity analysis in text and image tasks.
Limitations:
Explanations depend heavily on how the “local neighborhood” is defined. Small changes can produce radically different results. LIME explains a surrogate model-not the original one.
- SHapley Additive exPlanations (SHAP)
SHAP assigns feature contributions based on Shapley values from cooperative game theory.
What it shows:
How much each feature contributed to moving a prediction away from a baseline.
Strengths:
Theoretically grounded, consistent, especially effective for tabular data.
Limitations:
Assumes feature independence. Correlated features distort attribution. SHAP explains contribution-not causal reasoning.
Often, SHAP doesn’t validate a model-it exposes its flaws.
- Attention visualization
Attention mechanisms highlight which parts of the input a transformer weighted during computation.
What it shows:
Information routing patterns, not causal importance.
Strengths:
Helpful for debugging language behavior and spotting annotation artifacts.
Limitations:
High attention ≠ high importance. Models can perform well even with randomized attention.
At Coral Mountain, attention patterns are invaluable for diagnosing annotation issues-but dangerous when treated as ground truth explanations.
- Gradient-based methods (saliency maps, integrated gradients)
These compute how sensitive predictions are to small input changes.
What they show:
Local sensitivity of outputs to inputs.
Strengths:
Efficient, model-agnostic, visually intuitive.
Limitations:
Gradients can be noisy, saturated, or misleading. Integrated Gradients reduce some issues but introduce baseline assumptions.
- Concept-based explanations (TCAV and similar)
These test whether models rely on human-defined concepts rather than raw features.
What they show:
Whether specific concepts causally influence predictions.
Strengths:
Bridge between low-level features and high-level reasoning.
Limitations:
Require carefully defined concepts and curated examples. Expensive to scale.
How to validate explainable AI: theater versus genuine insight
Most teams deploy XAI tools and assume explanations are correct because they look technical.
This assumption is costly.
Recognizing explainability theater
Warning signs include:
- Feature rankings that change unpredictably
- Explanations contradicting domain knowledge
- Plausible narratives with no validation
If explanation quality is measured only by fidelity to the model-not by usefulness to humans-it’s theater.
Validation methods that matter
Fidelity testing
- Perturb features claimed to be important. Does behavior change accordingly?
- Compare multiple XAI methods. Broad agreement matters more than precision.
- Test stability under small input changes.
Utility testing
- Do explanations change stakeholder decisions?
- Do they reveal bugs, bias, or data issues?
- Do they lead to guideline revisions or data cleaning?
Human alignment
- Can domain experts judge explanation plausibility?
- Are explanations coherent across similar cases?
- Do counterfactuals behave as predicted?
Explanations that fail these tests are narratives-not insight.
What explainable AI reveals about data pipelines
Explainability often exposes data problems faster than accuracy metrics.
Annotation drift detection
Shifts in feature importance or attention patterns without performance changes often signal guideline drift or annotator inconsistency.
Spurious correlation discovery
Models may learn annotation artifacts-length, formatting, metadata-rather than task semantics. XAI surfaces these shortcuts.
Guideline ambiguity
Inconsistent explanations across similar inputs often reflect unclear annotation standards. Clarifying guidelines stabilizes both explanations and performance.
Quality calibration
Models trained to score annotation quality reveal implicit standards. Explanation analysis helps formalize those standards into measurable criteria.
Practical explainable AI guidance for AI training work
Explainability doesn’t just evaluate models-it evaluates annotation practices.
Strong annotators:
- Use explanation feedback to refine judgment
- Investigate unexpected attention or attribution patterns
- Treat edge cases as signals, not annoyances
As explanations make model learning visible, edge-case handling becomes disproportionately valuable.
Contribute to AGI development at Coral Mountain
As fine-tuning and modeling become more efficient, data quality and human judgment dominate performance outcomes.
Explainability closes the loop: it shows how human decisions shape model behavior.
If you bring domain expertise, analytical rigor, and the ability to judge subtle trade-offs, AI training work at Coral Mountain places you at the core of frontier AI development.
Thousands of contributors already support this infrastructure.
To get started:
- Visit the Coral Mountain application page
- Submit your background and availability
- Complete the Starter Assessment
- Receive your decision
- Begin contributing to live projects
No fees. High standards. One attempt.
If you understand why quality beats volume-and can demonstrate it-we want to work with you.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves, Vietnamese data…