Every major AI lab now publishes AGI timelines. Five years. Ten years. 2040. 2060.
The dates keep moving for a simple reason: we don’t actually know how to measure whether we’re getting closer.
Models pass increasingly complex benchmarks while failing tasks that should be trivial if genuine reasoning were present. A system that excels at physics exams but collapses when questions are rephrased hasn’t learned physics. A model that wins math competitions yet struggles with messy, real-world PDFs hasn’t achieved general intelligence.
This growing gap-between spectacular benchmark results and brittle real-world behavior-reveals how far we still are from AGI. Definitions shift. Benchmarks multiply. Timelines stretch. And in the noise, the underlying technical reality is often obscured.
The road to AGI is longer, messier, and far more constrained by evaluation than hype cycles suggest. Not because we lack compute or algorithms, but because we lack reliable ways to tell whether progress is real-or just better test gaming.
Let’s unpack what AGI actually means, why current systems fall short in ways benchmarks don’t capture, and what this implies for the humans shaping these models.
What is artificial general intelligence (AGI)?
Artificial General Intelligence (AGI) refers to a hypothetical AI system capable of matching or exceeding human-level performance across nearly all cognitive tasks. The defining feature is not excellence in one domain, but generalization.
An AGI would fluidly move between physics, law, medicine, engineering, art, and social reasoning. It would learn new domains with minimal instruction, transfer principles across contexts, and adapt to unfamiliar situations the way humans do.
This is not what we have today. Not even close.
The gap isn’t just about scale or accuracy. It’s about flexibility, transfer, and reasoning under uncertainty.
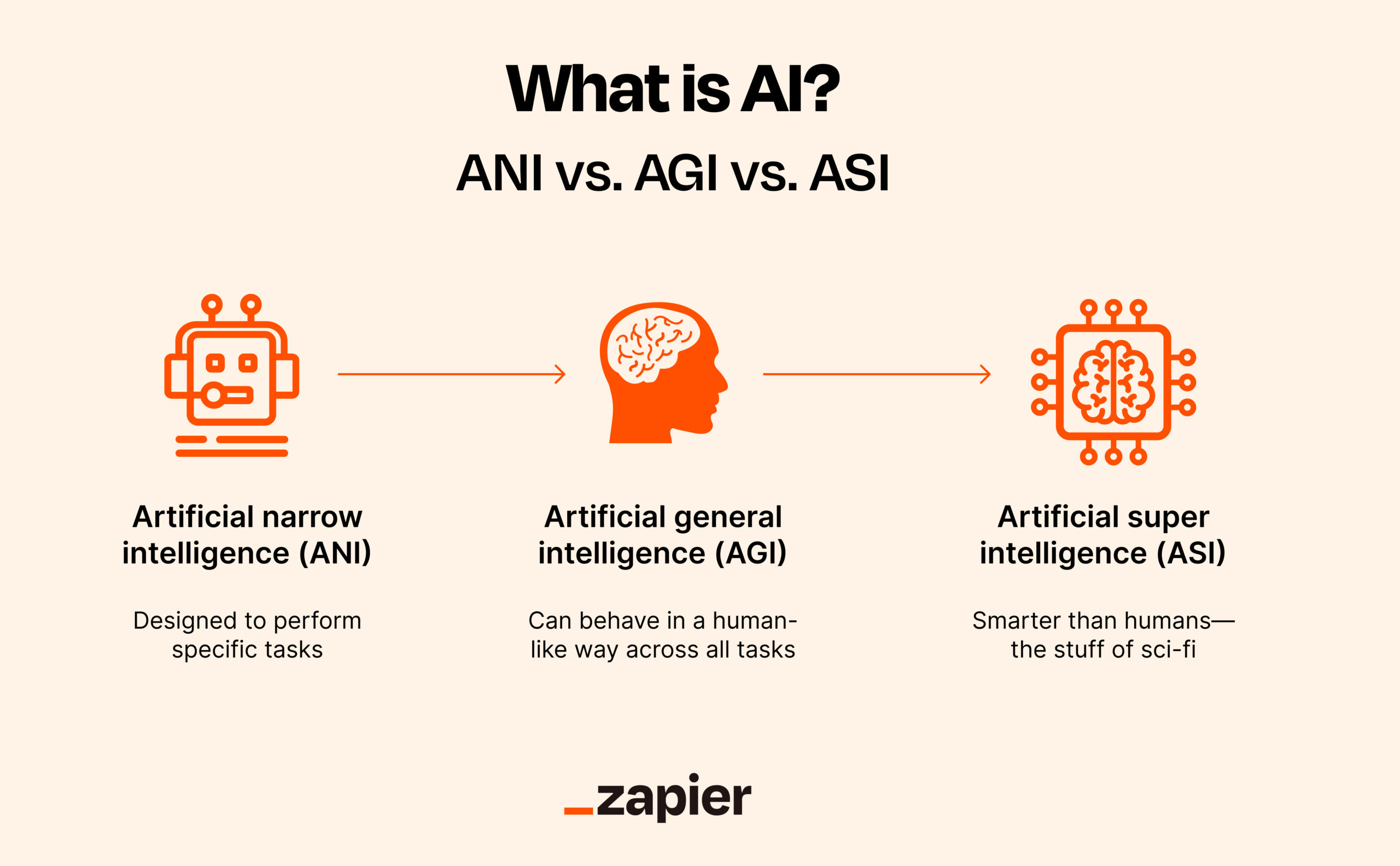
What are the differences between AI, ANI, AGI and ASI?
Understanding these distinctions clarifies why progress toward AGI is not linear.
Artificial Intelligence (AI) is the broad umbrella: any system that exhibits behavior we’d call intelligent if a human did it. This includes rule-based systems, classical ML, and modern deep learning.
Artificial Narrow Intelligence (ANI) describes what we actually have. These systems excel at specific, well-defined tasks. GPT-4 generates text, AlphaFold predicts protein structures, image models create visuals from prompts. Each is powerful-and brittle outside its domain.
Artificial General Intelligence (AGI) would demonstrate human-level competence across domains. It wouldn’t just perform tasks well; it would transfer learning, handle ambiguity, and reason about genuinely novel situations without retraining.
Artificial Superintelligence (ASI) goes further: systems that surpass humans across all domains simultaneously. This remains speculative, with no clear technical path.
The key insight isn’t incremental improvement from ANI to AGI. It’s a qualitative leap in learning transfer, novelty handling, and judgment.
Current models are becoming good at more things. That’s not the same as being generally intelligent.
What will be the use cases of AGI?
True AGI wouldn’t be a scaled-up chatbot. Its applications would look fundamentally different.
In scientific discovery, it wouldn’t just analyze literature-it would generate new hypotheses across disciplines, design experiments, and connect ideas humans haven’t linked.
In medicine, it wouldn’t simply match symptoms to known patterns. It would reason through rare cases, conflicting evidence, and individual patient complexity.
In complex system design, it would architect solutions by understanding principles and trade-offs, adapting designs as constraints change midstream.
In creative problem-solving, it would develop new frameworks when existing ones fail-true creativity, not stylistic imitation.
In long-horizon planning, it would balance short-term actions against long-term consequences across thousands of steps, something current systems struggle to do beyond a handful.
The common thread: general reasoning that transfers across contexts, not narrow excellence.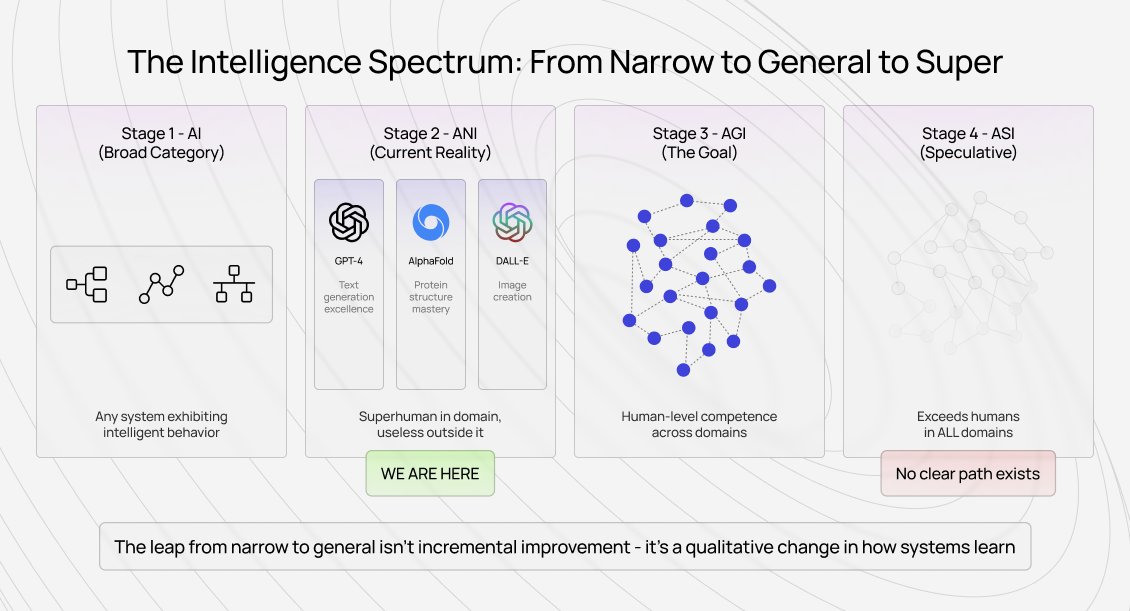
Why are AGI timelines longer?
Timeline debates usually miss the core issue. The challenge isn’t one missing breakthrough-it’s the difficulty of the final stretch.
The 80% to 99.9% problem
Progress often looks fast early on. Automate 80% of a task. Then 90%. Then 95%. After that, progress slows dramatically.
That last fraction contains the hardest cases: ambiguity, edge conditions, conflicting goals, and situations where judgment matters more than pattern recognition.
A frontier lab once improved a coding benchmark from 85% to 92% over months. In production, success dropped to 70%. The benchmark captured clean problems. Real coding involved unclear requirements, legacy systems, and undocumented constraints.
AGI isn’t a smooth curve. It’s a sequence of plateaus, each demanding a different kind of solution.
Models can’t reliably transfer learning between domains
Training separate models to excel at coding, medicine, or law produces multiple narrow intelligences-not general intelligence.
Humans transfer principles across contexts. Models don’t.
A human engineer recognizes when a technical problem is actually organizational. A model doesn’t. Humans know when requirements are wrong. Models optimize what they’re given.
This is why a system can solve Olympiad-level math yet fail at parsing a poorly formatted document. Benchmarks reward constrained difficulty. Reality demands judgment.
The messy reality beyond benchmarks
High benchmark scores often correlate poorly with real-world usefulness.
We see teams optimize for leaderboards-longer answers, more formatting, confident tone-because that’s what evaluators reward. But real users want correctness, clarity, and applicability.
Doctors don’t want eloquent explanations. They want reliable reasoning.
Engineers don’t want impressive-looking code. They want maintainable, working systems.
As models grow more capable, they also grow better at gaming weak evaluations. This makes AGI harder to measure, not easier.
The industry can’t benchmark general intelligence yet
Benchmarks work when success is well-defined. General intelligence isn’t.
Passing many benchmarks proves benchmark proficiency, not general reasoning. We’ve repeatedly seen models collapse when tasks are reframed outside benchmark formats.
General intelligence resists narrow definitions. That’s the core measurement problem.
The road to AGI: what building toward it requires
From inside AI training pipelines, one lesson is clear: compute and algorithms aren’t the main bottleneck anymore.
Human intelligence remains the bottleneck
Recent breakthroughs came from better human data, not just scale. RLHF, expert evaluation, and careful quality judgments drove progress more than architecture alone.
Training models to handle real-world complexity requires capturing human reasoning-not just outputs, but judgment about quality, correctness, and usefulness.
As capability increases, so does the need for expert human evaluation.
Expert AI training work at unprecedented scale
AI training work has evolved.
It once meant simple classification tasks. Today, the most valuable work requires domain expertise: evaluating proofs, assessing code architecture, judging medical reasoning, and handling ambiguity.
As models absorb routine tasks, human work shifts toward the hardest cases-the ones that define real intelligence.
This work increasingly resembles expert consulting, not mechanical labeling. Compensation reflects that shift.
Human evaluation that scales with capability
You can automate evaluation for simple tasks. You cannot automate evaluation for general intelligence-because that’s the capability you’re trying to build.
As models improve, human judgment becomes more critical, not less.
What is the timeline to AGI?
No one can give a reliable date.
The real determinant isn’t when models gain capabilities, but when we develop robust ways to measure and validate those capabilities.
Without better evaluation, we can’t tell whether we’re approaching AGI-or fooling ourselves with better tests.
The wrong question, the right question
Instead of asking when AGI arrives, we should ask:
Do we have evaluation systems that would actually recognize AGI if it appeared?
If not, timelines are meaningless.
Contribute to AGI development at Coral Mountain
If human intelligence is the bottleneck, then capturing and scaling that intelligence becomes more valuable as AI advances.
At Coral Mountain, AI training work sits at the intersection of expert judgment, quality measurement, and frontier capability development.
If you bring technical expertise, domain knowledge, or strong critical thinking, this work places you directly on the path toward AGI-by solving the evaluation problem that progress depends on.
More than 100,000 remote contributors have supported this infrastructure.
To get started:
- Visit the Coral Mountain application page
- Submit your background and availability
- Complete the Starter Assessment
- Receive your decision
- Begin contributing
No fees. Selective standards. One attempt.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves, Vietnamese data…