
You can spend months applying to platforms that pay $5/hour for repetitive microtasks – or you can spend one focused hour understanding what separates gig marketplaces from real AI technology companies, and access projects paying $20–$50+ per hour.
The distinction rarely appears in job listings.
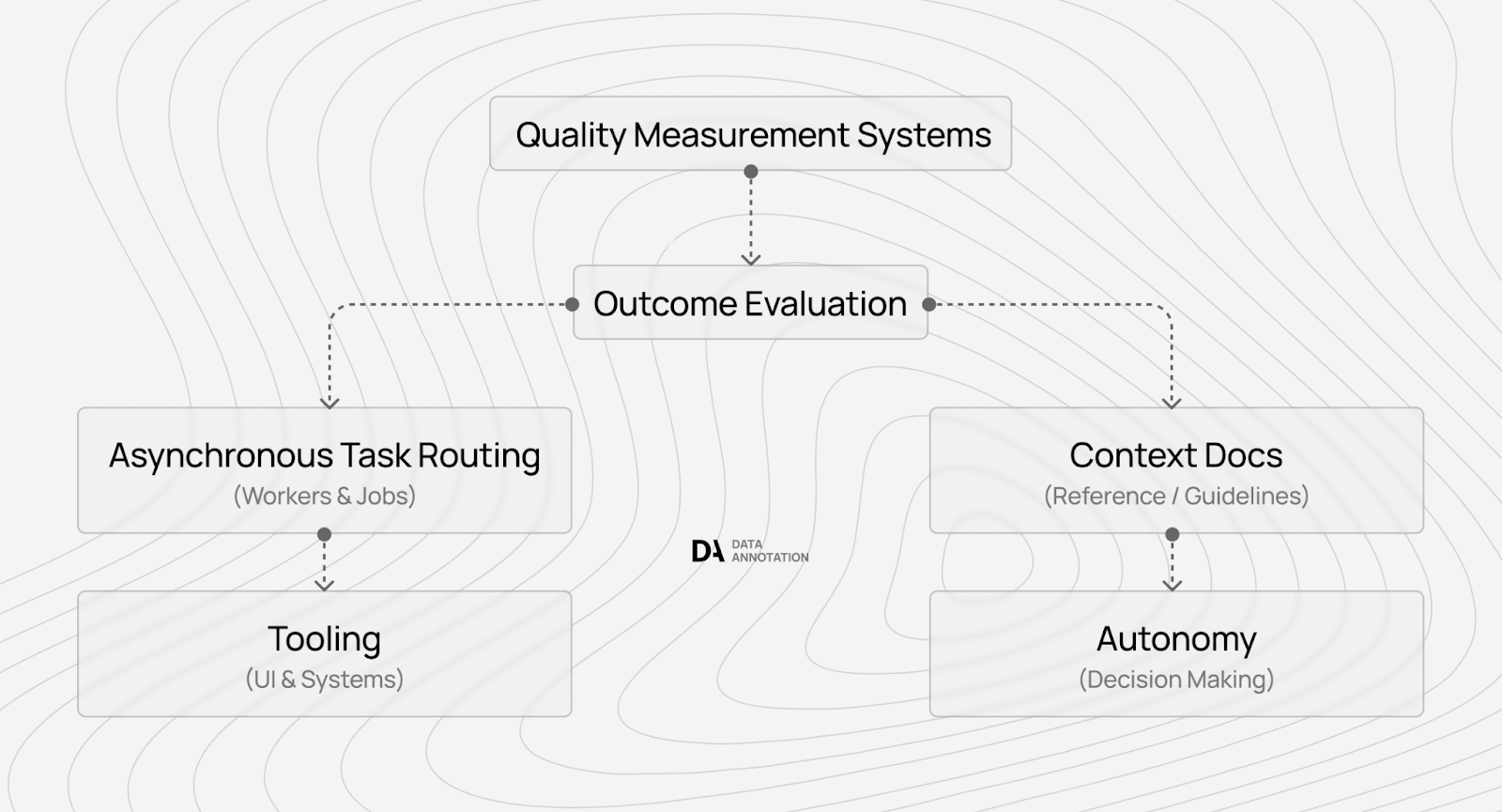
Many platforms in the AI training space look credible: they verify identities, pay on schedule, maintain polished websites, and collect positive reviews. Yet a large portion simply aggregate workers without building the systems required to measure or improve frontier AI quality – which ultimately drives compensation down.
After observing this industry from the inside and overseeing more than 100,000 remote contributors working on frontier AI systems, one pattern becomes clear: platforms that pay for expertise have the technology to measure quality. Those that don’t, compete on cost.
This guide explains how to access premium data annotation work, what signals to look for in a platform, what assessments truly evaluate, how to demonstrate judgment rather than box-checking, and why depth of expertise matters more than sheer volume of work.
- Build demonstrated capabilities that premium AI training requires
Many online guides suggest earning advanced degrees or learning programming languages. While education is valuable, credentials alone don’t reliably predict performance in high-quality AI training environments. Premium platforms assess demonstrated judgment in complex scenarios – not résumé bullet points.
Why credentials don’t always predict performance
Across industries, credentials often correlate imperfectly with real-world output:
- Some computer science PhDs struggle with production-ready code because academic training emphasizes theory over software engineering practicality.
- Ernest Hemingway never completed college, yet wrote prose more compelling than many English PhDs – because writing excellence requires discernment and taste.
- Emily Dickinson had no formal poetry education.
The pattern holds because premium AI training depends on evaluative judgment – not formal credentials.
Consider the well-known Google GoEmotions dataset, built from Reddit comments. It famously labeled “LETS FUCKING GOOOOO” as anger, when in context it expressed excitement.
The mistake occurred because annotators followed surface rules about profanity rather than interpreting intent. Premium contributors catch these errors. Credential-focused workers often miss them because they prioritize guideline compliance over contextual understanding.
What to practice beyond general work
To develop premium capability:
- Writing precision: Study why professional writing communicates clearly while amateur writing confuses – focus on structure and nuance, not just grammar.
- Critical reasoning: Evaluate arguments in domains you understand deeply. Identify assumptions and logical gaps.
- Edge-case handling: Build mental frameworks for unfamiliar situations instead of relying on intuition alone.
As you train, continuously evaluate yourself using four capability lenses:
- Taste – Can you distinguish between generic output and genuine insight?
- Street smarts – Do you recognize when rules fail in edge cases?
- Mental stamina – Can you analyze a single response carefully for 30 minutes if necessary?
- Judgment under ambiguity – Can you apply principles when guidelines are incomplete?
These skills develop through deliberate exposure to ambiguity – not through coursework alone.
Capability shifts in specialized tracks
Different premium tracks demand different evaluative strengths:
- Coding: Recognizing elegant architecture over brute-force solutions, and spotting hidden technical debt.
- STEM: Assessing reasoning quality and methodological rigor beyond factual correctness.
- Professional domains: Applying regulatory context and ethical standards in ambiguous situations.
If you already have domain experience, your advantage lies in applying evaluative frameworks you’ve internalized – not acquiring new credentials.
The goal isn’t rapid transformation. It’s proving, through assessment performance, that you can exercise sound judgment under production conditions.
- Avoid scams by selecting platforms that measure quality – not just count workers
Most applicants focus on avoiding obvious scams. The subtler risk is legitimate-looking platforms that commoditize expertise.
If two platforms advertise similar work but one pays $5/hour and another pays $50/hour, the difference isn’t generosity. It’s measurement capability.
Platforms that can only verify “task completed: yes/no” compete on cost. Platforms that quantify how much a contributor reduces hallucinations, catches edge cases, or improves reasoning quality can justify premium compensation.
Body shops vs. technology companies
Clear red flags include:
- Upfront training fees
- Compensation below $10/hour
- No transparent terms or assessment
- Pressure to start immediately
Premium platforms structure pay tiers according to measurable expertise. Higher rates correspond to verified differences in performance – not arbitrary pricing.
If onboarding focuses solely on background verification without testing actual capabilities, that signals the platform is counting labor supply rather than extracting expertise.
Verifying legitimacy through worker feedback
Beyond structural signals, check independent reviews:
- Ratings on Glassdoor or Indeed
- Discussions on r/WorkOnline
- Trustpilot comments
- Better Business Bureau complaint history
Consistent reports of reliable payment and structured evaluation processes are strong indicators of legitimacy.
- Pass assessments designed to measure judgment – not checkbox compliance
Many applicants fail qualification assessments not because they lack skill, but because they approach them like academic exams.
Premium platforms design assessments to evaluate how you think in ambiguous production conditions.
What distinguishes judgment from box-checking?
These assessments measure:
- Time allocation – Do you recognize when a case deserves deeper analysis?
- Reasoning transparency – Can you clearly explain why you reached a conclusion?
- Principle extrapolation – Can you apply rules to situations the rubric doesn’t explicitly cover?
- Consistency – Do your decisions reflect a systematic approach?
Most assessments take 60–90 minutes when done thoughtfully; specialized tracks may require longer. Allocate at least double the suggested time to avoid rushed mistakes.
Preparation strategy: prioritize reasoning clarity
Effective preparation means:
- Focusing on quality rather than speed
- Avoiding attempts to guess “expected” answers
- Clearly articulating your reasoning process
- Demonstrating structured, repeatable evaluation methods
For example, if a rubric prefers responses with citations, the checkbox approach rewards any citation. A judgment-based approach evaluates whether the citations genuinely support claims – recognizing that misleading citations are worse than none.
Why single-attempt policies exist
Some platforms allow only one attempt per assessment track. This protects measurement integrity. Multiple retries would reward test optimization rather than authentic capability.
The assessment reveals how you think under real conditions – not how well you iterate toward a passing score.
Preparation matters because you’re demonstrating your natural evaluative framework.
- Scale through expertise depth – not work volume
Commodity labor scales with hours worked. Premium AI training scales with expertise depth.
As AI models advance, simpler tasks become automated. The remaining work grows more complex – and more valuable.
Why the quality ceiling keeps rising
In earlier AI stages, tasks like simple sentiment labeling were easy and highly automatable.
Later, evaluating reinforcement learning preference pairs required nuanced judgments about helpfulness and honesty.
Now, frontier model work may involve analyzing multi-step reasoning chains or debugging logic breakdowns – tasks with a far higher quality ceiling and far lower automation risk.
As model capabilities increase, expertise becomes more valuable, not less.
What tier structures reveal
Compensation tiers reflect measurable differences in evaluative complexity:
- $20+ per hour: Strong writing clarity, critical thinking, and attention to detail.
- $40+ per hour: Coding or STEM domain evaluation – recognizing elegance, methodological soundness, and subtle errors.
- $50+ per hour: Professional-level judgment in law, finance, medicine, or other regulated fields.
The compensation jump reflects verification difficulty. General quality can be statistically validated. Expert-level quality requires deeper human verification – which commands higher pay.
Leverage existing expertise
Rather than attempting to enter unfamiliar domains, identify where your current background provides an evaluative edge.
- Coding professionals can detect maintainability risks beyond passing tests.
- STEM graduates can assess whether reasoning supports conclusions.
- Licensed professionals can evaluate contextual appropriateness under regulatory standards.
Preparation for specialization involves refreshing fundamentals and sharpening evaluative clarity – not reinventing your career.
As AI systems grow more capable, the gap between “passes automated checks” and “advances model capability” widens. That widening gap is where premium contributors operate.
Explore premium AI training jobs at Coral Mountain
Most platforms frame AI training as gig work – side income through repetitive microtasks. Coral Mountain approaches it differently: as direct contribution to frontier AI systems where contributor judgment meaningfully shapes model behavior.
When you evaluate AI responses for advanced training pipelines, your decisions influence how models balance helpfulness with truthfulness, how they interpret ambiguity, and how they generalize reasoning.
This work affects systems used by millions.
Moving from interest to earning involves five steps:
- Visit the Coral Mountain application page and select “Apply.”
- Complete the short form outlining your background and availability.
- Take the Starter Assessment evaluating critical thinking and attention to detail.
- Await the approval decision via email.
- Access your dashboard, select a project, and begin contributing.
There are no signup fees. Selectivity exists to maintain quality standards. Since assessments are typically limited to one attempt per track, prepare thoroughly before beginning.
If you understand why quality outweighs volume in advancing frontier AI – and you possess the expertise to demonstrate it – Coral Mountain represents a path to premium data annotation work aligned with that philosophy.