
Voice agents are evolving beyond rigid turn-based interaction toward continuous, real-time communication. In natural conversations, people rarely wait for the other party to finish speaking. They interrupt, revise their thoughts, clarify details, or introduce new constraints mid-sentence.
Modern full-duplex spoken dialogue systems (FDSDS) such as GPT-realtime-2025-08-28, Gemini Live-2.5-flash-native-audio, Grok Voice Agent, and Amazon Nova Sonic 2 are increasingly designed to process speech streams continuously instead of enforcing strict turn boundaries.
Full-duplex systems promise more natural human–machine interaction by allowing comprehension and generation to happen simultaneously. However, existing evaluation benchmarks largely fall into two categories:
- Turn-delimited evaluations that assess responses after a complete user utterance.
- Full-duplex evaluations that mainly measure floor-control behavior such as latency, overlap handling, and interruption detection.
What remains largely untested is whether models can maintain and revise their reasoning state when new information arrives during ongoing speech generation. This gap motivates the Dual-Stream Reasoning (DSR) failure modes examined in this work: Contextual Inertia, Interruption Amnesia, and Objective Displacement.
To address this limitation, Coral Mountain introduces EchoChain, a benchmark designed to evaluate real-time reasoning under pressure in full-duplex voice systems. EchoChain uses scenario-driven conversations where users interrupt responses with context-grounded updates, forcing the system to revise constraints while it is still speaking.
Beyond conversational AI evaluation, EchoChain also contributes to broader AI data ecosystems by supporting structured data collection, audio annotation, image annotation, photo annotation, video annotation, traffic annotation, natural data generation, and integration with off-the-shelf datasets used in multimodal model training.
From turn-based dialogues to continuous reasoning
Many dialogue benchmarks assume a half-duplex interaction model where only one speaker talks at a time and the system responds only after the user completes their utterance. This abstraction works well for text chat or push-to-talk interfaces, but it does not reflect the complexity of real conversations.
In real scenarios, users frequently adjust their requests while the assistant is already responding-for example: “Actually, change X to Y.” In such cases, the task input is no longer static. Correctness becomes an ongoing requirement. The model must continuously update its task state, preserve existing constraints, and integrate new information while generating its response.
While response latency and smooth turn-taking remain important, they are not sufficient for evaluating full-duplex systems. What needs to be measured is the model’s ability to reason continuously during interaction.
Instead of treating each dialogue turn as a static input-output pair, EchoChain simulates real voice interactions. Audio arrives as a stream, interruptions occur mid-response, and the system’s ability to adapt its reasoning in real time is captured and analyzed.
The evaluation framework deliberately introduces controlled interruptions during assistant responses and records the full conversational flow. By standardizing stimuli and timing, EchoChain enables fair comparisons across different models and architectures.
Performance is analyzed at the instance level and grouped into three primary failure categories. The evaluation pipeline follows a two-stage approach:
- Automated screening for rapid large-scale evaluation
- Targeted human review for accuracy and reliability
The hidden failure modes of voice agents

Interruption failure classifications. The red text highlights key audio assistant failures.
Interruptions significantly affect reasoning performance compared with traditional turn-based evaluation.
In early experiments, conversations that failed after an interruption were replayed without the interruption. Interestingly, 40.22% of these cases succeeded when the model was allowed to complete its response uninterrupted.
This indicates that many observed errors are specifically triggered by mid-generation updates. These failures are categorized into three Dual-Stream Reasoning patterns:
Contextual Inertia occurs when the model receives new information but continues reasoning as if nothing has changed.
Interruption Amnesia describes situations where the model initially acknowledges the update but later loses that information as generation continues, showing weak state persistence.
Objective Displacement occurs when the model treats the interruption as a new independent task, ignoring the original objective and producing an incomplete answer.
These patterns highlight an important limitation in current voice agents: they may appear fluent in conversation while still failing to maintain coherent reasoning across interruptions.
Why existing audio benchmarks miss this
Most current evaluation frameworks measure either turn-based accuracy or conversational fluency. While both metrics are valuable, neither directly isolates reasoning quality after interruptions occur.
The key issue is that interaction fluency is not the same as reasoning robustness. A system may smoothly acknowledge an interruption and continue speaking while still producing an incorrect response due to Contextual Inertia, Interruption Amnesia, or Objective Displacement.
Benchmarks that focus primarily on latency, overlap handling, or conversation flow may therefore overlook critical reasoning failures.
How EchoChain works
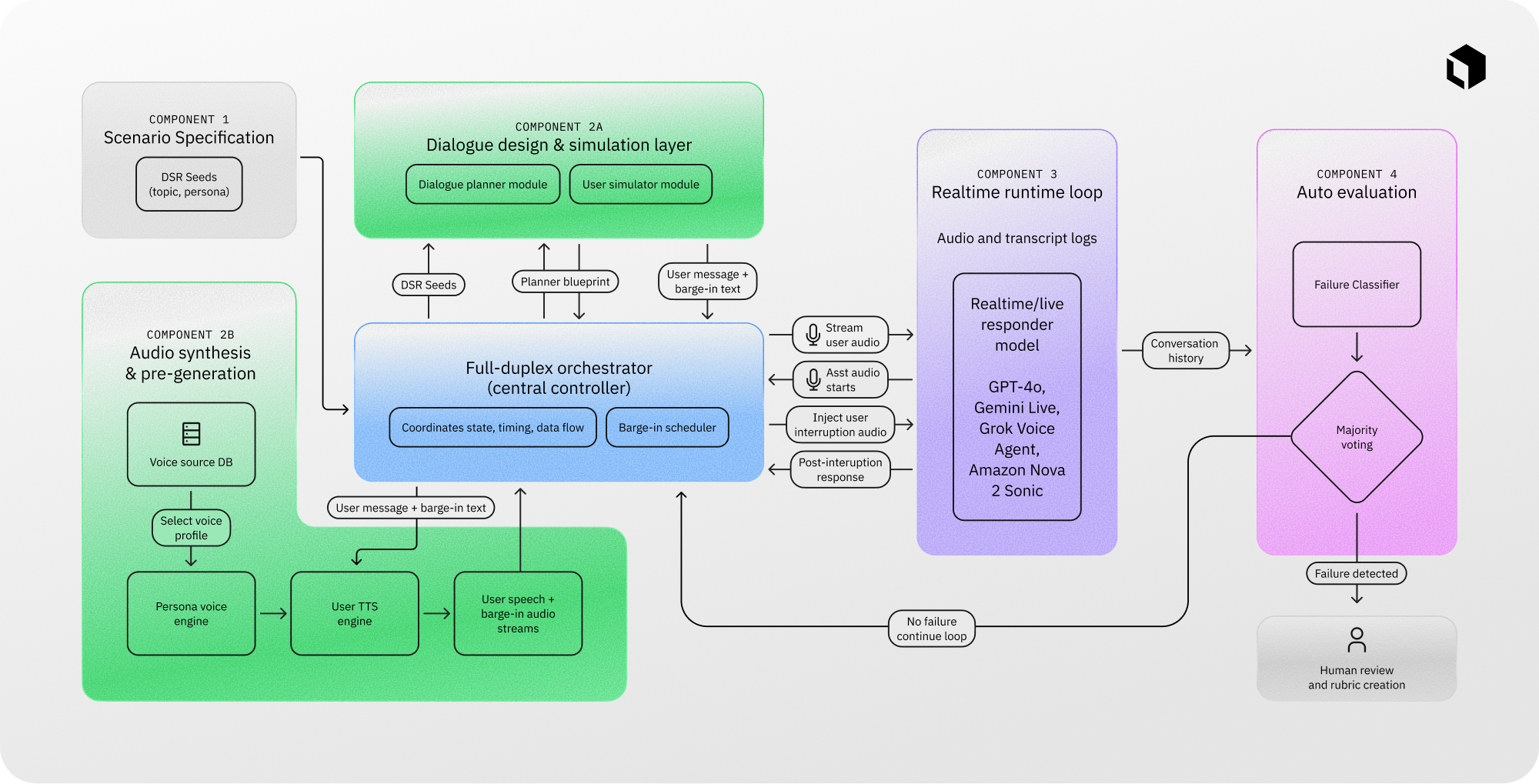
Within the EchoChain framework, interruptions are introduced as standardized inputs that are independent of the model architecture. The goal is to evaluate whether the assistant can integrate both the original context and the new constraints introduced during the interruption.
Scenario context, system instructions, and assistant persona remain consistent across runs. Context-grounded barge-ins are injected at deterministic moments relative to the start of assistant speech. This controlled setup enables detailed analysis of reasoning updates during ongoing generation while minimizing variability.
The framework evaluates several full-duplex audio models including GPT-realtime-2025-08-28, Gemini Live-2.5-flash-native-audio, Grok Voice Agent, and Amazon Nova Sonic 2.
The EchoChain system consists of four main components:
- Scenario specification
- Dialogue simulation and audio synthesis
- Real-time runtime execution
- Automated and human evaluation
A central orchestration module manages the conversation flow, streams audio inputs, records interaction traces, and routes potential failures into the evaluation pipeline.
EchoChain begins with a library of Dual-Stream Reasoning scenario seeds such as voice support calls, interview coaching sessions, and multi-constraint planning tasks. A planning module then generates dialogue structures designed to trigger interruption-sensitive situations.
User audio is synthesized using a Persona Voice Engine combined with a voice-cloning TTS system, ensuring consistent speaker identity throughout each session. Both the main utterance and interruption audio are generated before runtime execution begins. This design ensures deterministic injection timing and avoids synchronization drift during interruption windows.
Evaluation follows a staged process that balances scalability and accuracy. Each interaction is segmented into:
- pre-interruption output
- interruption content
- post-interruption continuation
An automated transcript classifier performs initial screening based on the Dual-Stream Reasoning taxonomy. Human reviewers then analyze flagged interactions by listening to the audio and reviewing transcripts, applying a structured evaluation rubric to produce final pass/fail labels.
EchoChain’s methodology can also support multimodal training workflows involving audio annotation, video annotation, photo annotation, image annotation, traffic annotation, and large-scale natural data collection, enabling integration with off-the-shelf datasets used for training conversational and perception models.
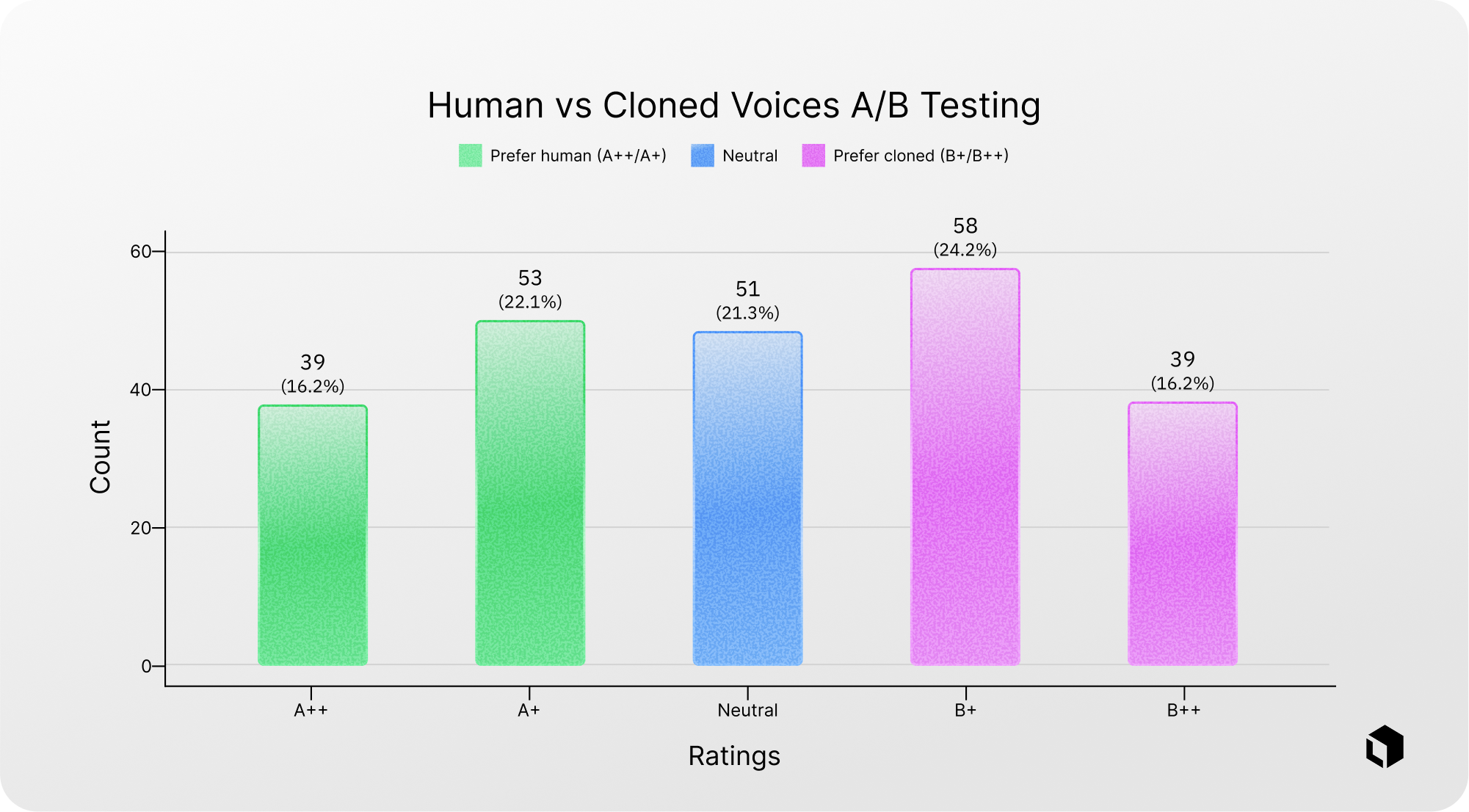
Voice cloning validation (A/B testing)
To ensure that synthesized voices accurately represent real conversational conditions, a blind A/B listening study was conducted. Participants listened to paired audio clips-one recorded by a professional voice actor and one generated by the cloning pipeline-without knowing which was which. They then rated which sounded more human using a five-point preference scale.
The overall rating distribution shows a nearly balanced preference between real and cloned voices. Many responses clustered around the “slight preference” and “neutral” categories rather than the extremes.
These results suggest that the cloned voices are difficult to distinguish from real human recordings in this context, making them suitable substitutes for user speech in benchmark testing.
What EchoChain reveals
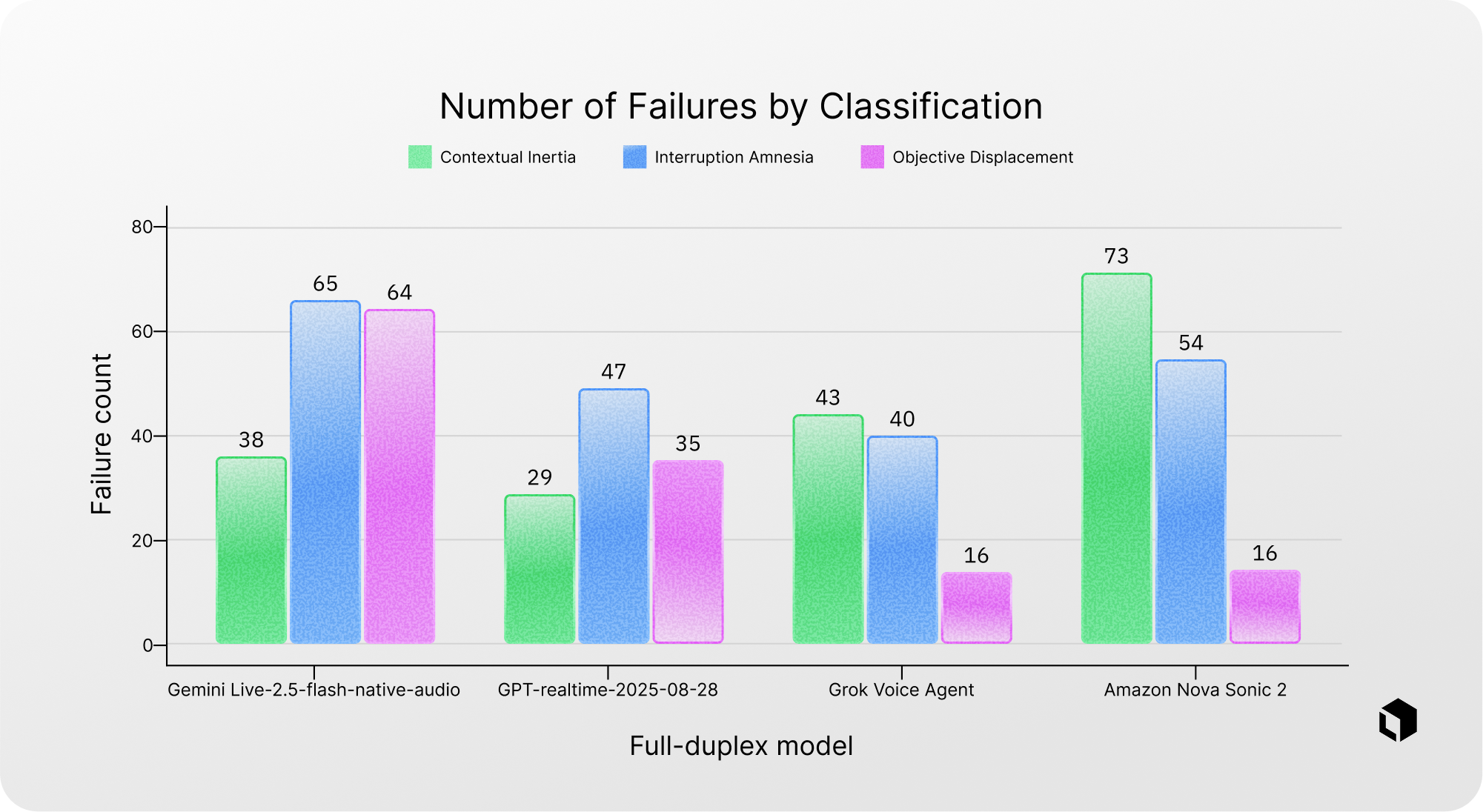
Across the evaluated models-including GPT-realtime-2025-08-28, Gemini Live-2.5-flash-native-audio, Grok Voice Agent, and Amazon Nova Sonic 2-several patterns emerge.
Many models struggle to integrate interruption information effectively. In some cases, the interruption is partially or completely ignored.
A particularly common weakness is the inability to maintain state persistence while generating responses. The most frequently observed failure pattern is Interruption Amnesia, where the interruption alters task constraints but the model later loses this updated information.
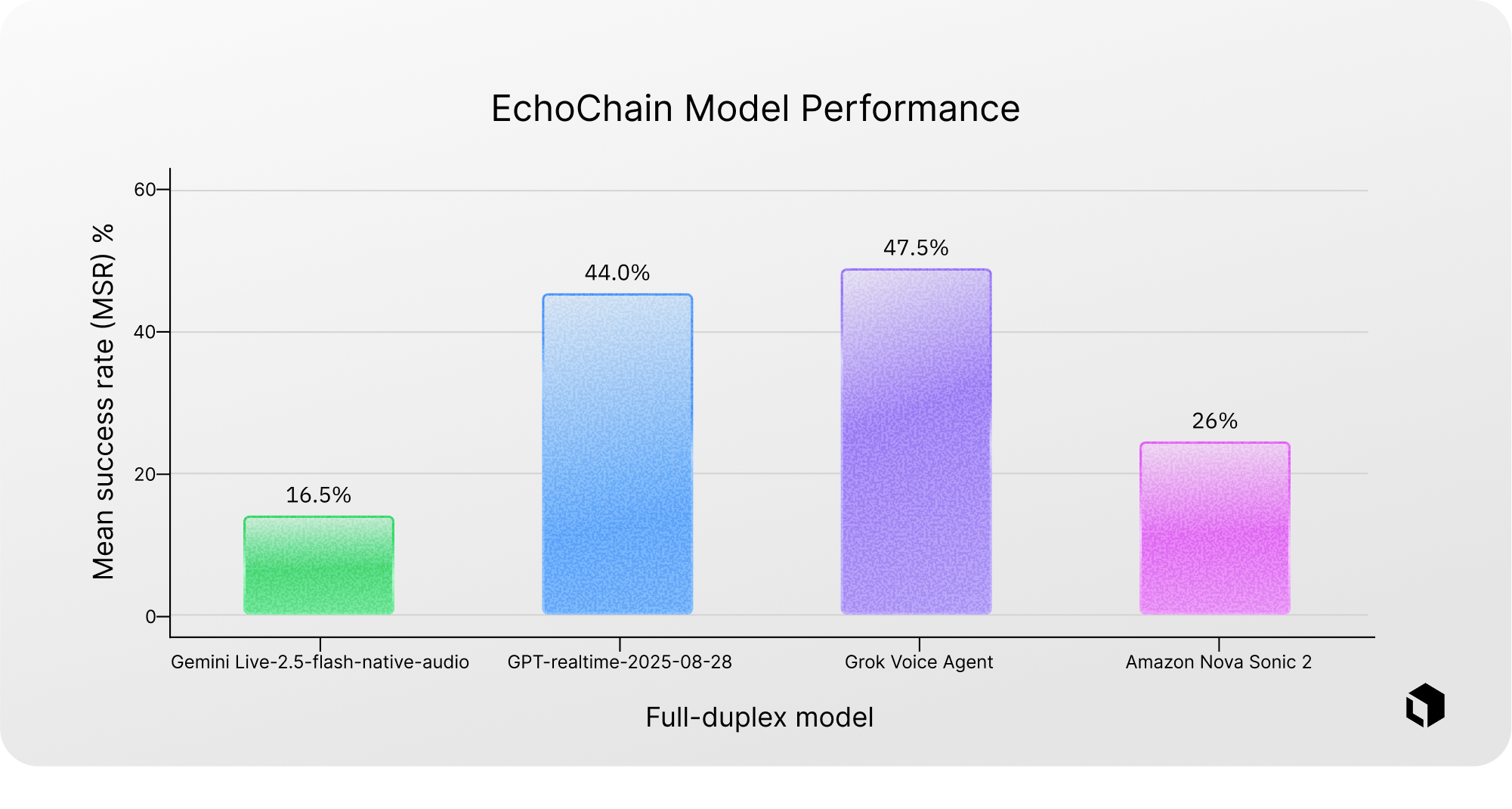
The best-performing model achieved a Dual-Stream Reasoning pass rate of 47.5%, indicating that significant improvements are still possible in handling interruptions during real-time dialogue.
Failure analysis also shows model-specific tendencies. For example, Gemini Live-2.5-flash-native-audio demonstrates a higher proportion of Objective Displacement failures, while Amazon Nova Sonic 2 shows an unusually high rate of Contextual Inertia errors.
When evaluating overall success rates across a curated dataset of 200 scenarios, Gemini Live-2.5-flash-native-audio achieved a pass rate of 16.5%, Amazon Nova Sonic 2 achieved 26%, GPT-realtime-2025-08-28 reached 44%, and Grok Voice Agent achieved the highest rate at 47.5%.
Even with the best-performing systems, success rates remain below 50%, highlighting substantial room for improvement in real-time reasoning capabilities.
Why reasoning under pressure matters
As voice assistants become more advanced and autonomous, full-duplex communication will likely become the default interaction model. People naturally interrupt, clarify details, and modify their requests during conversation.
In such environments, correctness is not only about delivering a final answer but about maintaining accurate reasoning while the task evolves in real time.
For AI researchers and system designers, this introduces a new and under-measured challenge: whether models can reconcile previous commitments with newly introduced information.
EchoChain is designed to isolate this capability under controlled experimental conditions. By treating interruptions as standardized, model-agnostic events and focusing specifically on reasoning rather than conversational fluency, the framework enables clearer identification of reasoning failures during concurrent dialogue.
Organizations working with conversational AI, multimodal training pipelines, and annotation ecosystems-including data collection, photo annotation, video annotation, image annotation, traffic annotation, natural data generation, and off-the-shelf datasets-can benefit from this approach when evaluating the robustness of voice-enabled systems.
If you would like to learn more about how Coral Mountain can adapt the EchoChaframework for your specific research or production needs, feel free to get in touch. The full research paper will be released soon on arXiv.