
How labeled sensor data powers object detection, scene understanding, and decision-making in autonomous vehicles
Autonomous vehicles (AVs) are among the most transformative innovations in modern transportation. At their core, these systems depend on computer vision to interpret the world around themf-detecting lane markings, identifying pedestrians, recognizing traffic signs, and making real-time decisions.
What makes these capabilities possible is data annotation.
Every action an AV takes is learned from annotated datasets that include thousands of labeled images, LiDAR point clouds, and radar signals. These labels teach machine learning models how to interpret raw sensor inputs, enabling them to differentiate between vehicles, pedestrians, road structures, and other critical elements in complex driving environments.
This article explores how data annotation underpins computer vision in AVs, covering sensor inputs, annotation methods, quality requirements, and the challenges of maintaining accuracy in safety-critical systems.
Vision systems in autonomous vehicles: The inputs
Autonomous vehicles rely on a combination of sensors to build a complete understanding of their surroundings. Each sensor contributes unique information and requires specific annotation techniques for effective model training.

Camera data for object detection
Cameras are the closest equivalent to human vision in AV systems. They capture high-resolution RGB images that provide information about color, texture, shape, and contrast. These inputs are essential for:
- Reading traffic signs and signals
- Detecting lane markings
- Identifying vehicles, pedestrians, cyclists, and animals
- Interpreting road conditions and hazards
To train models on camera data, several annotation techniques are used:
- Bounding boxes: Rectangular regions that localize objects like cars or pedestrians
- Polygon segmentation: Detailed outlines capturing the exact shape of objects
- Keypoint annotation: Specific landmarks (e.g., joints, wheels) used to understand posture or orientation
These annotations must be applied consistently across large datasets to ensure models perform reliably under varying lighting and environmental conditions.
LiDAR and radar for depth and obstacle sensing
LiDAR (Light Detection and Ranging) generates 3D point clouds by emitting laser pulses. Unlike 2D imagery, LiDAR provides precise depth and spatial structure, making it highly effective for:
- Measuring distances to objects
- Detecting curbs, poles, and road boundaries
- Mapping 3D positions of vehicles and pedestrians
- Navigating complex terrain
Common LiDAR annotation techniques include:
- 3D cuboid annotation: Defining objects in three-dimensional space
- Semantic segmentation: Assigning labels to each point (e.g., road, vehicle, pedestrian)
Radar complements LiDAR by performing well in challenging conditions such as rain, fog, or darkness. Although less detailed, it strengthens perception reliability. Radar annotation typically focuses on identifying object returns and associating them with categories, especially for moving objects.
Sensor fusion: Multi-modal labeling
No single sensor can fully capture every scenario. That’s why AV systems rely on sensor fusion-combining inputs from cameras, LiDAR, radar, and GPS.
Multi-sensor annotation involves:
- Synchronizing timestamps across sensor streams
- Aligning coordinate systems between 2D and 3D data
- Projecting labels across modalities (e.g., mapping a 3D LiDAR box onto a camera image)
This process requires advanced platforms capable of handling cross-modal data while maintaining label consistency. It becomes especially critical in dynamic environments with occlusions or overlapping objects.
Annotating the vision: Techniques that train the model
Once sensor data is collected, annotation transforms it into structured datasets suitable for machine learning.
Bounding box and instance segmentation
Bounding boxes remain a foundational technique for object detection and classification. By labeling large volumes of objects such as vehicles and pedestrians, models learn to recognize them in real time.
However, bounding boxes can be limiting in dense or complex scenes. Instance segmentation addresses this by isolating each object individually, even when multiple objects belong to the same category.
This enables AV systems to:
- Maintain safe distances from individual road users
- Navigate crowded environments
- Handle occlusions and partial visibility more effectively
Interpolation and object tracking
Driving is continuous, not static. Models must understand how objects move across time.
Object tracking ensures that the same entity is consistently labeled across video frames, allowing models to learn motion patterns. Interpolation reduces manual effort by predicting annotations between keyframes.
These techniques help AVs:
- Anticipate pedestrian movement
- Avoid collisions with moving vehicles
- Understand trajectories, speed changes, and behavior over time
Pre-annotation and quality assurance
As datasets grow, manual annotation alone becomes inefficient. Pre-annotation-where AI generates initial labels-helps accelerate the process. Human annotators then refine these outputs, combining speed with accuracy.
Modern annotation workflows also include strong quality assurance mechanisms:
- Multi-annotator consensus checks
- Layered review processes
- Honeypot tasks to evaluate annotator performance
These practices ensure that datasets are both scalable and reliable for training critical systems.
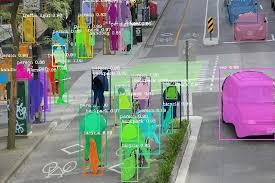
The cost of poor annotations
In autonomous driving, annotation errors are not just technical issues-they can translate into real-world safety risks.
Examples of critical failures include:
- Misclassifying a pedestrian as background
- Missing a partially obscured stop sign
- Failing to detect bicycles due to insufficient training data
Poor annotations often result in:
- False positives: Detecting objects that aren’t there
- False negatives: Missing actual obstacles
- Unstable behavior: Sudden braking or incorrect maneuvers
To avoid these outcomes, annotation must meet strict standards:
- Accuracy: Labels must precisely match real-world objects
- Consistency: Uniform labeling across frames and scenarios
- Validation: Rigorous QA before training
Even small inconsistencies-such as using different labels for the same object-can degrade model performance.
Annotation platforms like Coral Mountain help maintain quality through structured workflows, validation systems, and issue tracking, ensuring that datasets remain consistent and production-ready.

Annotation quality can be maintained using tools like issue management, validation checks and proper annotation workflows.
Conclusion
Achieving full autonomy is not just about better hardware or faster computation-it depends heavily on better data, and more importantly, how that data is labeled.
Computer vision in autonomous vehicles relies on:
- Multi-sensor inputs: Combining cameras, LiDAR, radar, and GPS for comprehensive awareness
- Advanced annotation techniques: From bounding boxes to segmentation and tracking
- Robust QA systems: Ensuring every label reflects real-world conditions accurately
As the industry evolves, annotation processes are becoming more sophisticated. AI-assisted labeling, pre-annotation pipelines, and real-time quality checks are enabling faster and more accurate dataset creation at scale.
Ultimately, the intelligence of an autonomous vehicle is defined by the data it learns from. Investing in high-quality data annotation doesn’t just improve model performance-it directly shapes the safety and reliability of next-generation transportation systems.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….