
See how you can address quality assurance challenges in data annotation through multi-annotator validation, issue tracking, and smart automation.

The COCO dataset contans a lot of mislabeled images. In this example, only a few sheep are labeled, and the rest are marked as crowd
COCO Labeling error example
The COCO dataset contains numerous labeling inconsistencies. In this example, only a portion of the sheep are correctly labeled, while the rest are grouped as “crowd.”
As AI systems become more advanced, the need for high-quality labeled data continues to rise. Yet one persistent issue still slows down progress: inconsistent annotations.
Whether you’re working with images, LiDAR point clouds, or medical scans, accuracy is critical. In sectors like autonomous driving and healthcare, even small labeling errors can significantly impact model performance—and in some cases, introduce real-world risks.
Take the example of a startup developing autonomous delivery vehicles. Despite processing a large volume of annotations, their QA team faced two ongoing challenges:
- Lengthy quality review cycles
- Inconsistency between annotators
Both directly reduced training efficiency and model accuracy.
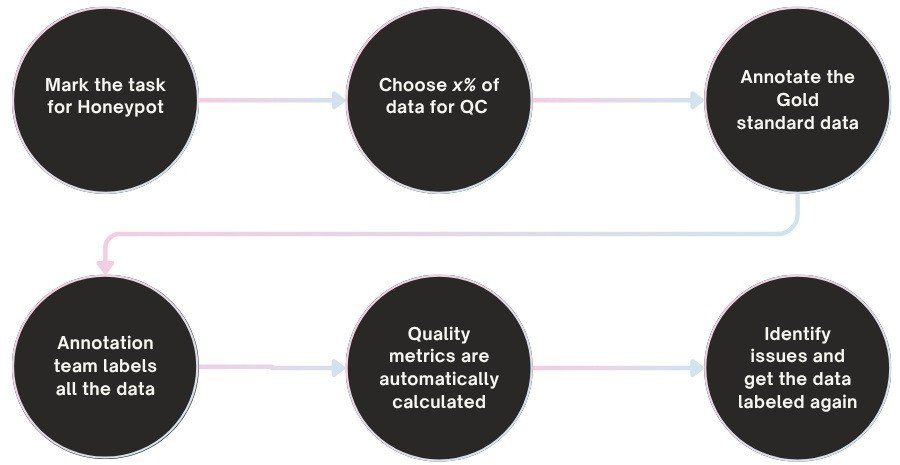
A typical QC workflow that assures datasets are of high quality
The problem – Poor quality annotations
When annotation is rushed or lacks proper quality control, datasets become noisy and inconsistent. This leads not only to weaker model performance but also to wasted time, as teams must revisit and correct flawed labels.
In high-stakes environments like healthcare or autonomous systems, these delays can significantly slow development.
Low-quality annotations create ripple effects across the entire machine learning pipeline. Models may appear to train successfully but fail when deployed in real-world conditions.
Key issues include:
- Inconsistent labeling standards introduce conflicting signals during training
- Mislabeling of edge cases reduces model robustness in real-world scenarios
- Errors compound over time, requiring costly retraining
- Debugging becomes increasingly complex when annotation quality varies across teams or timeframes
- Biased or incomplete labels can introduce systemic errors and limit generalization
Annotation QC Workflow
A well-designed quality control workflow ensures datasets remain reliable and production-ready.
Sign up today and explore how a structured annotation platform can help you build high-quality datasets more efficiently and accelerate your AI development.
The solution: Built in QC tools
By adopting a QA-first approach, Coral Mountain enables teams to identify issues early—before they become costly bottlenecks.
Its validation-first workflows are designed to detect inconsistencies in real time, allowing teams to resolve problems before they reach production. Instead of reviewing every annotation manually, reviewers can focus only on outliers and edge cases, significantly improving efficiency.
- What is multi-annotator validation?
Traditional QA processes rely on reviewing annotations after submission. Multi-annotator validation changes this by assigning the same data to multiple annotators from the start.
This approach allows systems to:
- Automatically compare annotations
- Measure agreement levels
- Detect discrepancies early
Coral Mountain supports this with built-in metrics such as majority voting and overlap scoring. When inconsistencies arise, they are flagged immediately—long before they affect model training.
Example: If multiple annotators label a vehicle differently in a LiDAR dataset, the system compares their bounding volumes and highlights mismatches for review.
- What are honeypot tasks?
Honeypot tasks are pre-labeled samples inserted into workflows without annotators knowing. They serve as a real-time benchmark for measuring annotator accuracy.
With native honeypot support, Coral Mountain automatically evaluates annotator performance based on these known samples. This helps teams:
- Identify where additional training is needed
- Detect underperforming annotators early
- Maintain consistent quality across large teams
- Reviewer interface that focuses on the edge cases
Instead of reviewing every annotation, reviewers can concentrate on samples with low agreement or flagged issues.
The reviewer interface in Coral Mountain allows teams to:
- Compare multiple annotation versions side by side
- Identify and flag conflicts
- Approve or correct labels with full context
This targeted workflow reduces review time while ensuring only high-confidence data moves forward.
Why does QA-first annotation matter?
A reactive QA process only addresses problems after they occur. A proactive, validation-first approach prevents them altogether.
With Coral Mountain’s workflow:
- Issues are detected before reaching production
- Reviewers focus on high-risk cases instead of all data
- Models are trained on clean, reliable datasets from the beginning
The result: fewer errors, faster iteration cycles, and better-performing models.
Other tools that can improve accuracy further
Coral Mountain goes beyond basic labeling—it provides a full ecosystem designed to enhance data quality and streamline large-scale annotation projects.
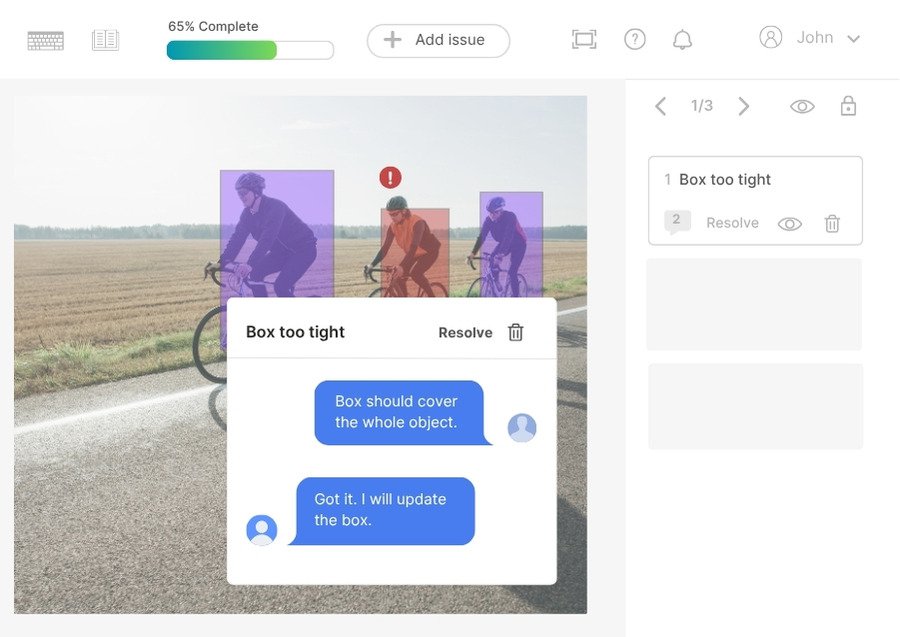
Issue tracking dashboard
Annotation tasks can be ambiguous—images may be blurry or objects partially hidden. With built-in issue tracking, annotators can flag these cases directly within the platform. This ensures edge cases are escalated appropriately rather than overlooked.
Reviewer scoring system
Not all annotators perform at the same level. Tracking performance metrics such as accuracy, speed, and consistency helps teams identify strengths and areas for improvement. This feedback loop enables better training and smarter task assignment.
Auto-labeling
For video or sequential image tasks, manually labeling every frame is inefficient. Coral Mountain supports interpolation between keyframes and AI-assisted labeling for repetitive patterns. This reduces manual effort and minimizes fatigue-related errors.
Conclusion: Data quality is a workflow problem — Coral Mountain fixes that
Coral Mountain is more than a labeling tool—it’s a comprehensive quality assurance system.
With features like multi-annotator validation, honeypot evaluation, and streamlined reviewer workflows, teams can reduce manual review effort while improving dataset reliability.
- Less guesswork
- Higher agreement
- Faster delivery
If you’re looking to improve annotation quality and reduce review time, Coral Mountain provides the structure and tools to make it happen.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….