The quiet failure modes that appear when multimodal annotation moves from pilots to real-world systems.
Most multimodal annotation workflows don’t collapse in obvious ways. They tend to degrade quietly.
In pilot phases, everything appears under control. Teams annotate camera data, LiDAR point clouds, depth maps, and radar inputs. Models train successfully. Metrics improve. Confidence builds, and the system is approved for rollout.
But once the system reaches production, the context changes entirely. Data is no longer used just for experimentation-it directly powers real systems, decisions, costs, and sometimes safety-critical outcomes. At this stage, even small inconsistencies begin to matter.
Multimodal annotation refers to labeling data from multiple sensor sources in a unified way. In production, those labels are no longer abstract-they directly influence deployed models, user experiences, and operational accountability. Errors don’t remain in test environments; they surface as delays, rework, and reduced trust.
Across autonomy, robotics, geospatial systems, and medical imaging, the pattern repeats. Workflows that performed well during pilots begin to strain-not because teams fail, but because the annotation systems were never designed to handle production-scale multimodal complexity.
What fails first is not the team. It’s the system behind the annotation process.
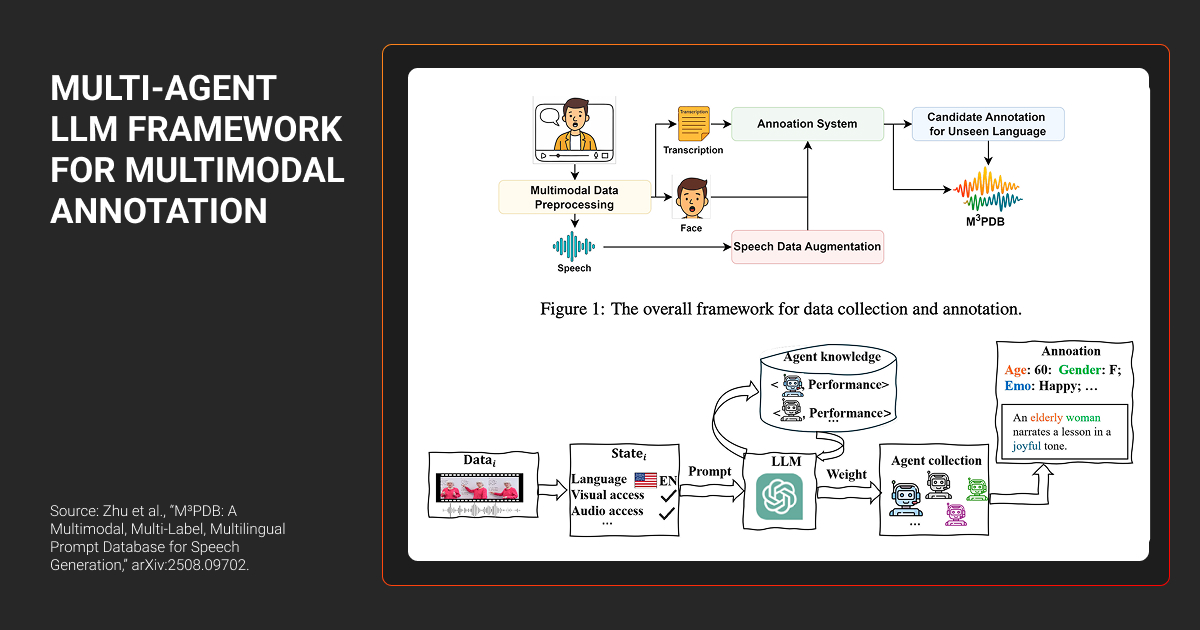
Sensor fusion for camera and LiDAR
Labels stop meaning the same thing across data sources
Early on, teams often annotate each data type independently. Camera images may be labeled in one tool, LiDAR data in another, and additional sensor data elsewhere. Each workflow works in isolation.
The issue emerges when these annotations are expected to align.
Different sensors capture the same object in fundamentally different ways. A car might appear as a clean rectangle in an image, but as a sparse cluster of points in LiDAR. Both representations are valid-but not identical.
When labeled separately, the meaning of that object gradually diverges. Boundaries no longer align, and edge cases are interpreted inconsistently.
In autonomous systems, this shows up when camera annotations appear precise, but fail to match LiDAR boundaries. Teams may question the model or sensor performance, when the real issue lies in inconsistent labeling logic across modalities.
In fields like medical imaging, the consequences are even more serious. The same structure may appear clearly in one scan and ambiguously in another. Without alignment across modalities, models inherit that inconsistency-leading to potential misinterpretation.
Teams often respond by refining guidelines or retraining annotators. But this isn’t fundamentally a human issue-it’s a system design problem. Without a unified annotation framework, consistency depends on manual coordination, which doesn’t scale.
Systems designed for multimodal workflows treat all sensor inputs as a single connected environment. Consistency is enforced structurally, not through repeated instructions or human memory.
Review effort grows, but confidence shrinks
As multimodal datasets scale, complexity increases. Objects may be partially visible in one sensor but clear in another. Signals may conflict. Edge cases multiply.
The instinctive response is to add more review layers. At first, this feels like a safeguard. More reviewers should mean higher quality.
In practice, it often produces the opposite outcome.
Reviewers repeatedly encounter ambiguous cases. Decisions get revisited without resolution. Disagreements circulate instead of converging. Teams invest more time reviewing data, yet confidence in that data declines.
This pattern becomes especially visible in production environments. For example, in autonomous systems, rare road scenarios still slip through despite extensive review pipelines-slowing progress without improving trust.
The issue isn’t the amount of effort. It’s where that effort is applied.
Traditional review models assume all data should be treated equally. In multimodal systems, that assumption breaks down. What matters most is uncertainty-where sensors disagree and human judgment is actually required.
Validation-first workflows address this by surfacing uncertainty early. Instead of reviewing everything, teams focus on the small subset of data that truly needs attention.
Confidence improves not because more data is reviewed, but because the right data is prioritized.
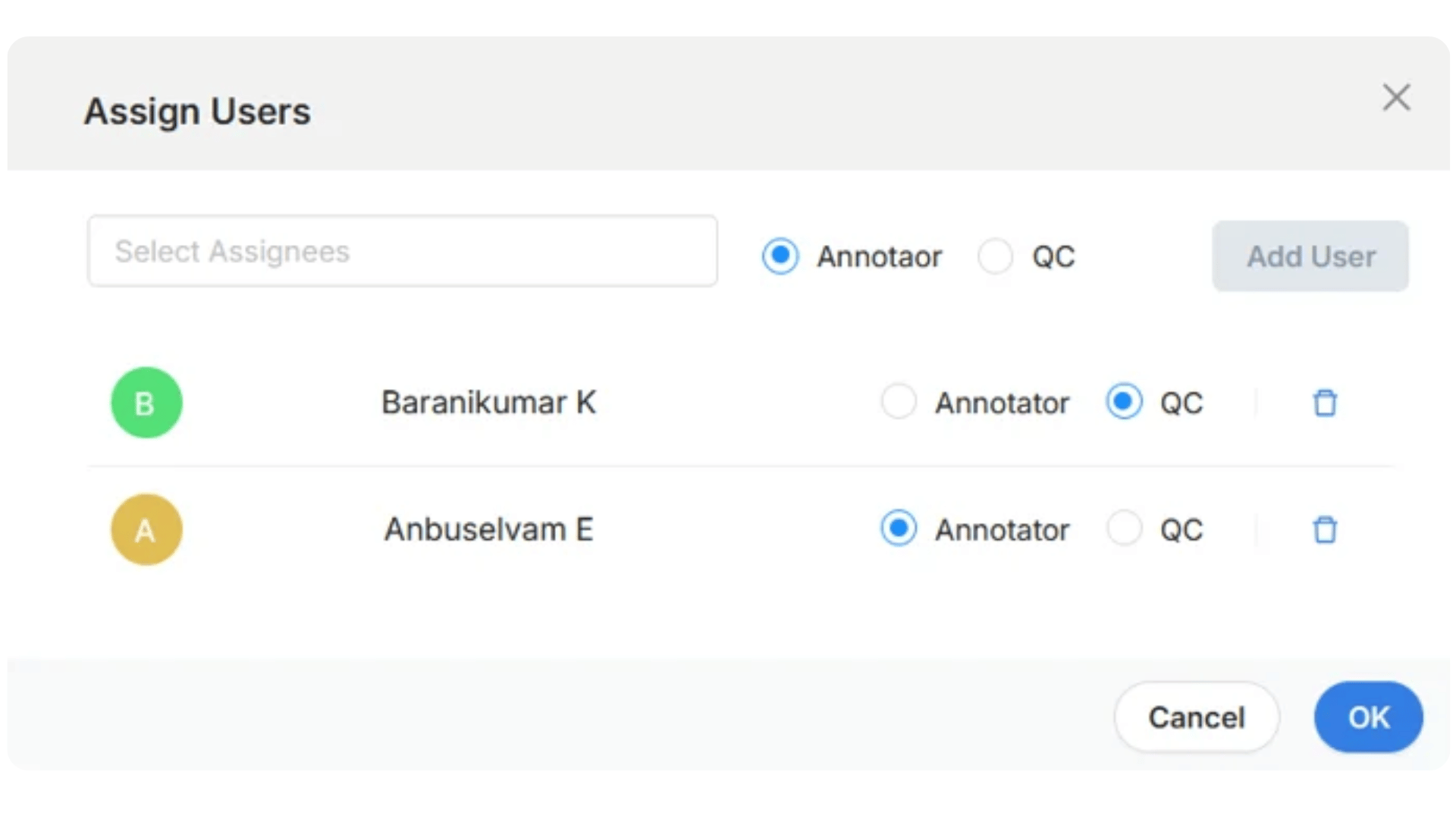
Disagreements are discovered too late
One of the most costly failure patterns in production annotation is late discovery.
This happens when teams assume annotations are correct until something downstream fails. A model behaves unpredictably. Performance plateaus. A deployment test reveals inconsistencies.
Only then does the investigation begin.
By that point, the cost is already high. Teams must trace errors back through datasets, re-evaluate annotations, and sometimes redo large portions of labeled data. Timelines slip, and trust in the system weakens.
In robotics, this often appears as repeated retraining cycles driven by subtle inconsistencies. Systems hesitate, fail in edge scenarios, or require overly cautious safety constraints.
Late discovery is expensive because small issues accumulate over time. What could have been resolved early becomes embedded deeply within production pipelines.
Production-ready annotation systems surface disagreements during the labeling process itself. Conflicts become visible while they are still easy-and inexpensive-to resolve.
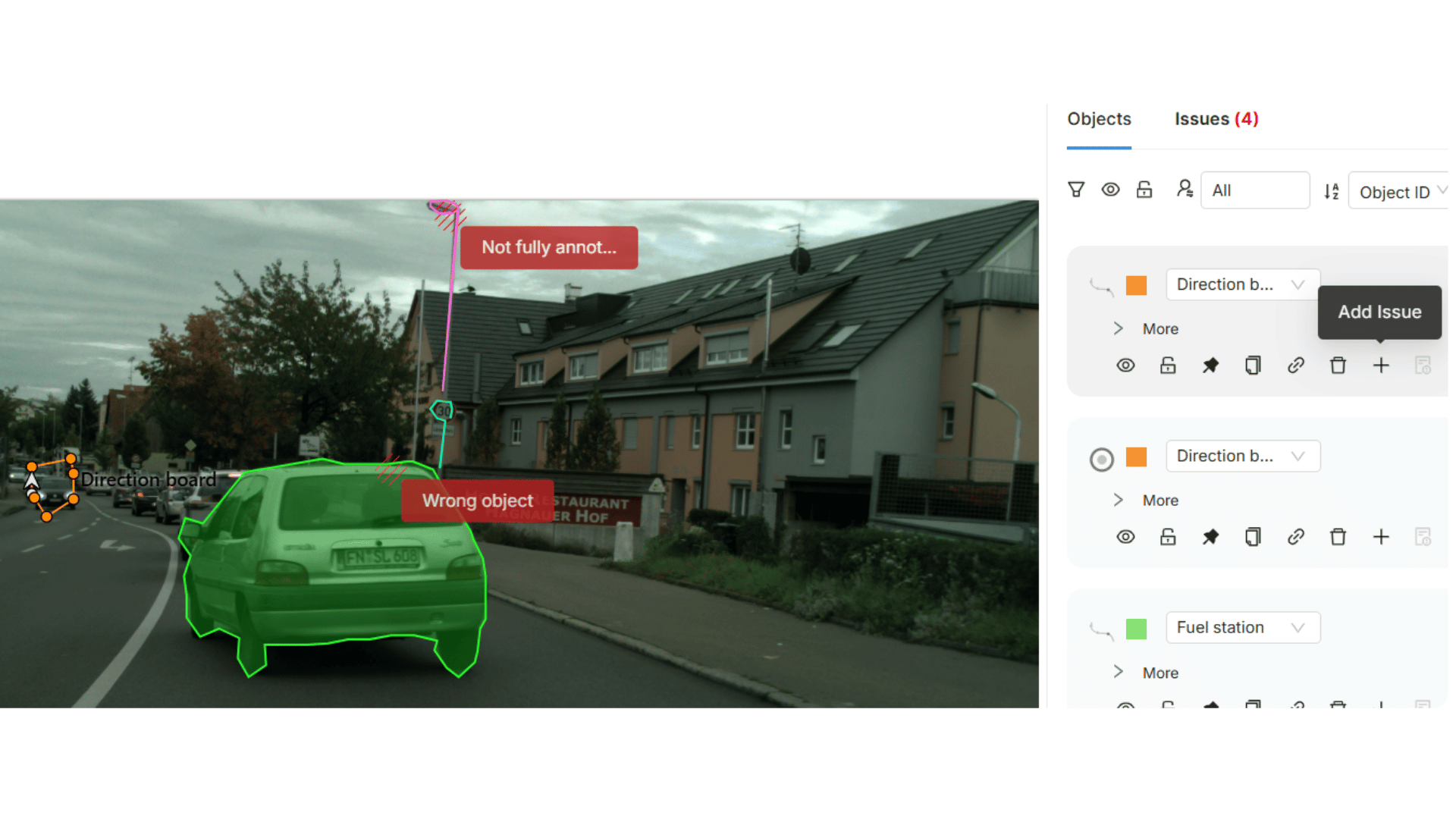
Quality becomes inconsistent across teams and time
Production introduces scale and parallel workflows. Internal teams collaborate with external vendors. New annotators join. Projects span months or years. Guidelines evolve.
Over time, consistency begins to drift.
Decisions that were once clear become ambiguous. Without systems to preserve and enforce those decisions, annotation quality diverges. Current labels may no longer align with those created earlier, even within the same project.
This is particularly risky in regulated or safety-critical industries. In autonomy and robotics, inconsistencies across teams can lead to unpredictable behavior. In healthcare, variation across annotators or institutions can undermine dataset reliability.
Maintaining consistency isn’t about freezing rules-it’s about managing change deliberately. Annotation systems must ensure that updates are visible, controlled, and applied uniformly.
When workflows, quality rules, and validation logic are embedded into the system itself, consistency no longer depends on individuals. It becomes part of the infrastructure.
Quality assurance starts slowing down delivery
Eventually, quality assurance can shift from being a safeguard to becoming a bottleneck.
Operations teams face a difficult tradeoff: move faster and risk errors, or slow down for QA and miss delivery targets. This tension creates friction between engineering, QA, and leadership.
At this stage, teams need more than just review processes-they need operational visibility and control without disrupting workflows.
When QA is treated as a final checkpoint, it will always slow things down. In production environments, quality must be integrated into the workflow itself.
Checks should happen continuously, not at the end.
When QA is embedded into the process, it enables speed instead of restricting it. Teams no longer have to choose between delivery timelines and data reliability.
How teams avoid these failures with multimodal annotation
Teams that successfully scale multimodal annotation tend to follow a few consistent principles.
They rely on unified systems rather than fragmented tools, ensuring that all data types are handled together instead of reconciled later.
They surface quality issues during annotation, not after model failures, and focus review efforts on uncertainty rather than volume.
They enforce consistency through workflow design, allowing processes to evolve without introducing drift.
These approaches reflect a broader reality: production annotation requires systems built for scale, change, and accountability-not pilot-stage workflows.
Where Coral Mountain fits
Coral Mountain is designed for teams operating at this exact transition point-from experimentation to production.
At this stage, multimodal data complexity, delivery pressure, and quality risks intersect. Coral Mountain provides a unified platform for annotating images, video, and LiDAR data within a single system, ensuring consistency across sensor types.
Its quality-first approach embeds validation directly into workflows. AI-assisted tools such as pre-annotation, interactive segmentation, and 3D cuboid labeling improve consistency while identifying uncertainty early-before it impacts models or deployments.
Flexible workflows allow annotation guidelines to evolve without introducing inconsistency, while managed services ensure uniform standards across teams and over time.
Most importantly, the system is designed to scale seamlessly. The same validation logic used in pilot phases continues into production, eliminating the gap where many systems typically break.
Multimodal annotation doesn’t fail because teams grow-it fails when fragile workflows encounter real-world complexity. Coral Mountain is built to support that transition with stability, consistency, and control.
Coral Mountain Data is a data annotation and data collection company that provides high-quality data annotation services for Artificial Intelligence (AI) and Machine Learning (ML) models, ensuring reliable input datasets. Our annotation solutions include LiDAR point cloud data, enhancing the performance of AI and ML models. Coral Mountain Data provide high-quality data about coral reefs including sounds of coral reefs, marine life, waves….